關係形 데이터베이스의 設計에서 重複을 最少化하게 데이터를 構造化하는 프로세스를
定規化(Normalization)
라고 한다. 데이터베이스 정규화의 目標는 以上이 있는 關係를 再構成하여 작고 잘 組織된 關係를 生成하는 것에 있다. 一般的으로 定規化란 크고, 제대로 組織되지 않은 테이블들과 關係들을 작고 잘 組織된 테이블과 關係들로 나누는 것을 包含한다. 정규화의 目的은 하나의 테이블에서의 데이터의 揷入, 削除, 變更이 定義된 關係들로 인하여 데이터베이스의 나머지 部分들로 傳播되게 하는 것이다.
關係形 모델
의 發見者인
에드거 F. 커드
는 1970年에 第 1 定規化(
1NF
)로 알려진 정규화의 槪念을 導入하였다.
[1]
에드거 F. 커드
는 이어서 第 2 定規化(
2NF
)와 第 3 定規化(
3NF
)를 1971年에 定義하였으며,
[2]
1974年에는
레이먼드 F. 보이스
와 함께 보이스-코드 定規化(
BCNF
)를 定義하였다.
[3]
4NF
以上의 定規化는 以後에 다른 理論家들에 依해서 定義되었으며, 가장 最近에 紹介된 定規化는 2002年에
크리스토퍼 J. 데이트
,
허그 다위
,
니코스 로렌츠
에 依해 紹介된 第 6 定規化(
6NF
)이다.
[4]
非公式的으로 關係形 데이터베이스
테이블
(컴퓨터 工學的 表現으로는
關係
)이 第 3 正規(
3NF
)畫家 되었으면
定規化되었다
라고 한다.
[5]
3NF 테이블의 大部分이 揷入, 變更, 削除 異常이 없으며,
3NF
테이블의 大部分이
BCNF
,
4NF
,
5NF
이다.(그러나 一般的으로
6NF
는 아니다.)
데이터베이스 디자인 標準 가이드는 데이터베이스가 完全히 定規化되게 디자인되어야 한다; 그 뒤에 一部가
性能
上의 理由로
非正規火
될 수는 있다.
[6]
그러나,
데이터 웨어하우스
디자인을 위한
觀點 모델링
과 같은 一部 모델링 規則에서는 例外的으로 비 定規化된 디자인을 推薦한다. 卽 大規模 部分에서의 디자인은
3NF
가 아니다.
[7]
정규화의 目的
[
編輯
]
1970年
에드거 F. 커드
에 依해 定義된
第 1 정규형
의 基本的 目的은
1次 論理
에 基盤을 둔 "普遍的 데이터 附言어"에 依해 데이터가 質疑되고 造作되게 하기 위해서였다.
[8]
(
SQL
이 이 데이터 附言어의 代表的인 例이지만, 정작
에드거 F. 커드
는 이 言語는 深刻한 缺陷을 가지고 있다고 생각하였다.)
[9]
에드거 F. 커드
에 依해 定義된 第 1 定規化(1NF)의 目的은 아래와 같다.
- 1. 考慮되지 않은 揷入, 更新, 削除 依存에서부터
關係
의 集合을 排除한다.
- 2. 새로운
資料型
이 나타날 때, 關係들의 集合의 再構成의 必要性을 낮추고, 그로 인하여 應用 프로그램의 生命週期를 延長한다.
- 3. 使用者에게 關係 모델을 더욱 意味있게 한다.
- 4. 關係들의 集合을 質疑의 統計로부터 中立的이게 한다. 質疑들은 時間이 지남에 따라 變更되기 때문.
- ?E.F. Codd, "Further Normalization of the Data Base Relational Model"
[10]
이 目的들을 아래에서 더욱 仔細히 알아본다.
데이터베이스의 變更時 異常 現象 除去
[
編輯
]
 更新 以上
. Employee 519는 다른 레코드에서 다른 住所를 가지고 있다.
更新 以上
. Employee 519는 다른 레코드에서 다른 住所를 가지고 있다.
 揷入 以上
. 新入 敎授인 Dr. Newsome은 아직 授業을 配定받지 않았다는 理由로 敎授 情報를 管理하는 이 테이블에 Newsome 敎授 레코드를 揷入할 수가 없다.
揷入 以上
. 新入 敎授인 Dr. Newsome은 아직 授業을 配定받지 않았다는 理由로 敎授 情報를 管理하는 이 테이블에 Newsome 敎授 레코드를 揷入할 수가 없다.
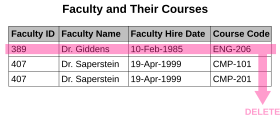 削除 以上
. ENG-206 授業이 끝나 該當 레코드를 削除하면, Dr. Giddens 敎授의 모든 情報가 削除된다.
削除 以上
. ENG-206 授業이 끝나 該當 레코드를 削除하면, Dr. Giddens 敎授의 모든 情報가 削除된다.
테이블 修正(更新, 揷入, 削除)市, 願치 않던 副作用이 發生할 수 있다. 이 副作用은 充分히 定規化되지 않은 테이블에서 發生할 수 있는데, 充分히 定規化 되지 않은 테이블은 아래와 같은 特性들이 있다:
- 같아야 하는 情報가 複數 個의 行에서 表現되면, 更新 時 論理的인 矛盾을 招來할 수 있다. 例를 들어, "職員 保有技術"이라는 테이블에서 모든 레코드가 職員 ID, 職員 保有技術, 職員 住所를 包含하고 있다고 하면, 特定 職員의 住所 變更 詩 여러 個의 레코드를 함께 修正해야 한다(그 職員이 保有한 모든 保有技術에 對해 레코드가 修正되어야 한다). 成功的인 更新이 이루어지지 않을 境遇-卽, 變更된 職員의 住所가 그가 가지고 있는 레코드 中에서 一部는 變更되었으나, 一部는 變更되지 않을 境遇- "職員 保有技術" 테이블은 矛盾 狀態가 된다. 卽, 그 特定 職員의 住所가 무엇인가에 對한 質問에 對해서 混同스러운 答案을 내놓게 된다. 이런 現象을 갱신 以上이라고 한다.
- “敎授와 그들의 講義”라는 테이블에서 敎授 ID, 敎授 이름, 敎授 任用일자, 授業 코드를 가지고 있다고 하자. 새 敎授를 任用하였을 境遇, 그가 맡은 講義가 없으면 授業 코드가 널(빈값)이어서 授業 코드가 識別컬럼(널 非許容)인 이 테이블에 追加할 수가 없게 되는데, 이런 現象을 삽입 以上이라고 한다.
- 어떤 情報를 削除하는데, 削除되면 안 되는 다른 事實이 함께 削除되는 現象이 있을 수 있다. 例를 들어, “敎授와 그들의 講義”라는 위 예제에서 Dr. Griddens 敎授가 ENG-206 授業을 臨時로 中斷하고자 하면, 이런 異常現象이 發生한다. 다시 말해 그가 맡은 授業 情報가 記錄된 레코드들을 削除하는 境遇, 敎授 情報 全體가 사라지게 되는데, 이런 現象을 삭제 以上이라고 한다.
데이터베이스 救助 擴張時 再 디자인 最少化
[
編輯
]
定規化된 데이터베이스 構造에서는 새로운 데이터 兄의 追加로 因한 擴張時, 그 構造를 變更하지 않아도 되거나 一部만 變更해도 되는 境遇가 있다. 이는 이 데이터베이스와 연동된 應用 프로그램에 最小限의 影響만을 주며, 應用 프로그램의 生命을 延長시킨다.
使用者에게 데이터 모델을 더욱 意味있게
[
編輯
]
定規化된 테이블들과 定規化된 테이블들間의 關係들은 現實世界에서의 槪念들과 그들間의 關係들을 反映한다. 卽 데이터 모델을 使用者에게 더욱 意味(informative)있게 한다.
多樣한 質疑 支援
[
編輯
]
定規化된 테이블은 一般的인 目的의 質疑에 適合하다. 이는 테이블에 對하여 細部事項이 豫測되지 않은 將來의 質疑를 包含한 어떠한 質疑도 支援한다는 意味이다. 反對로 正規化되지 않은 테이블은 (向後 發生할 수 있는) 어떤 質疑들은 支援하지 않을 수 있다.
例를 들어서, 顧客이 가지고 싶은 冊들의 目錄을 가지고 있는 온라인 書店을 생각해보자. 分明하게 豫想되는 質疑 -- 顧客이 願하는 冊은 무엇인가? --는 顧客이 가지고 싶은 冊들의 目錄 테이블에 著者와 題目이 있으면 된다.
이 테이블 디자인은 그 한 質疑에 對해서는 答할 수 있다. 그러나 다른 豫想되거나 關心있는 質疑들은 答할 수 없다: 顧客들이 가장 選好하는 冊은? 어떤 顧客들이 2次 世界大戰 스파이들에 對해서 關心있는가? 이 質疑에 對한 答을 求하기 위해서는 데이터베이스와 完全히 分離되어 이 質疑를 다루는 소프트웨어를 具現하여야 하며, 이 소프트웨어의 目標는 한가지이다: 비 定規化된 項目을 定規化한다.
定規化된 테이블에서는 豫測되지 않는 質疑라고 하여도 純全히 데이터베이스의 테두리 안에서 쉽게 答辯이 可能하다.
예제
[
編輯
]
顧客들의 信用카드 使用 內譯을 表現한 테이블을 假定하자. 이 테이블이 第 1 定規化가 안 되었을 境遇, 데이터의 質疑와 造作은 必要 以上으로 複雜해진다:
| 顧客
|
使用內譯
|
| 洪吉童
|
| 去來番號
|
일자
|
殘高
|
| 12890
|
2010-10-14
|
?87
|
| 12904
|
2010-10-15
|
?50
|
|
| 최철수
|
| 去來番號
|
일자
|
殘高
|
| 12898
|
2010-10-14
|
?21
|
|
| 한영미
|
| 去來番號
|
일자
|
殘高
|
| 12907
|
2010-10-15
|
?18
|
| 14920
|
2010-11-20
|
?70
|
| 15003
|
2010-11-27
|
?60
|
|
各 顧客들마다, 去來의
反復
이 있다. 그래서 顧客의 去來에 對한 質疑에 答하기 위해서는 아래의 2段階가 必要하다:
- 各 去來들을 調査하기 위해서 하나 以上의 顧客들의 去來들의 모임으로부터 各 去來를 抽出하여 그룹化
- 位 첫 段階의 結果로부터 質疑의 結果를 導出
例를 들어서, 모든 顧客들에 對하여 2010年 10月에 이루어진 모든 去來의 去來量(돈)의 合을 求하기 爲해서는 :
- 各 顧客들로부터 顧客들의
去來
의 모임을 各 去來들로 抽出
- 일자
가 2010年 10月인 去來들의
殘高
의 合을 救한다.
에드거 F. 커드
는 이러한 데이터 構造의 複雜性이 完全히 除去되었을 때 質疑가 (
使用者
와
應用 프로그램
에 依해서)표현되고 (
DBMS
에 依해서) 遂行됨에 있어서 더욱 强力하고 柔軟해진다고 보았다. 위 構造를 定規化하면 아래와 같다:
| 顧客
|
去來番號
|
일자
|
殘高
|
| 洪吉童
|
12890
|
2010-10-14
|
?87
|
| 洪吉童
|
12904
|
2010-10-15
|
?50
|
| 최철수
|
12898
|
2010-10-14
|
?21
|
| 한영미
|
12907
|
2010-10-15
|
?18
|
| 한영미
|
14920
|
2010-11-20
|
?70
|
| 한영미
|
15003
|
2010-11-27
|
?60
|
이제 各 行은 各 信用카드 去來를 의미하며, DBMS는 位 質疑에 對해서 2010年 10月에 該當하는 모든 行을 求해서 그들의 殘高를 合하면 된다. 이 데이터 構造는 모든 값이 同等한 立場을 가지며, DBMS에 直接的으로 反映되어 質疑에 潛在的으로 參與할 수 있게 된다; 以前의 狀況에서는 各 값이 下位 레벨 構造로 묶여서 質疑時 따로 取扱되어야 했다. 이런 理由로 定規化된 디자인은 一般的인 目的의 質疑에 適合하며, 非正規化된 디자인은 그렇지 않다.
背景 知識 : 正義
[
編輯
]
- 函數 從屬性
- 關係 스키마 中에서 어느 屬性君의 값이 定해지면 다른 屬性君의 값이 定해지는 것. A, B가 各各 關係 R의 屬性인 境遇, 任意 時點에서 A의 어떤 값도 반드시 B의 하나의 값에 對應되지만, B의 하나의 값이 A의 複數의 값에 對應되는 境遇에 B는 A에
函數 從屬
이라고 하며 A→B와 같이 表記한다. 例를 들어, "職員" 테이블이 "職員 ID" 屬性과 "職員 生日" 屬性을 가질 때, {職員 ID}->{職員 生日} 또는 {職員 生日}은 {職員 ID}에
函數 從屬
이다. 實際로는 {職員 生日}李 null 이거나 어떤 {職員 生日}에도 對應되지 않을 수 있으므로 맞지 않을 수도 있으나, 여기에서는 {職員 ID}는 正確히 하나의 {職員 生日}만 갖는다고 假定한다.
- 自明한 函數 從屬性
- 屬性들의 部分集合이 函數 從屬性을 가질때, 自明한 函數 從屬性(FD)이라고 한다. {職員 ID}->{職員 生日} 裏面 {職員 ID, 職員 住所}->{職員 生日} 은 自明하다.
- 完全函數 從屬性
- A, B가 各各 關係 R의 屬性이고 B가 A에 函數 從屬(A→B)인 境遇, A의 任意의 部分 集合에 對하여 B의 어떤 값도 A의 部分 集合의 값에 對應하지 않으면 B는 A에 完全函數(敵) 從屬이라고 한다.
- 履行函數 從屬性
- A, B, C가 各各 關係 R에 相互 重複되지 않는 屬性(다만, A는 1次 키 以外의 屬性)인 境遇에, A가 B에 函數 從屬的이 아니면 이때 C는 A에 履行函數 從屬이라고 한다. 第2정규형(2NF)의 關係에 履行函數 從屬性이 있는 境遇, 그것을 排除하고 分解한 關係를 第3정규형(3NF)이라고 한다. A->B 이고 B->C 일 境遇에만 A->C 裏面 履行函數(敵) 從屬이라고 한다.
- 다치 從屬性
- 다치 從屬性
(MVD)은 어떤 레코드의 存在가 다른 레코드의 存在로 이어짐을 意味한다. 多値從屬性은->>으로 標示하는데, R{A,B,C}일 때 (A,C)->>{B}≡(A) ->{B} 成立한다. , A->>B이면 A->>C도 成立하고 A->>B│C이다. (Fagin整理에 따라) R{A,B,C}에서 多値從屬 A->>B│C이면 R1{A,B}와 R2{A,C}로 무손실 分解가 可能하다. 이를 第4정규형(4NF)의 關係에 있다고 말한다.
- 조인 從屬
- 조인종속(JD)는 릴레이션 R이 그의 프로젝션 A,B,.....,Z의 調印과 同一하면 R은 JD*(A,B,....,Z )를 滿足한다. 이때 A,B,....,Z는 R의 애트리뷰트에 對한 部分集合이다. 다시말해서 테이블 R이 R의 屬性의 部分集合을 가지는 여러 個의 테이블들을 調印하여 만들어질 수 있을 때, R은 調印 從屬性을 가진다고 한다. 이를 第5정규형(5NF)이라고 한다.
- 슈퍼 키
- 슈퍼키는 레코드를 唯一하게 識別해낼 수 있는 屬性들의 集合이다. 한 個의 테이블은 여러 個의 슈퍼키를 가질 수 있다.
- 候補 키
- 候補 키
는 슈퍼 키에서 레코드를 唯一하게 識別하는데 있어서 必要없는 屬性을 除去한 슈퍼 키의 部分集合이다.
예제 :
{이름},{나이},{住民登錄 番號},{電話番號} 屬性을 가지는 테이블에서 슈퍼키는 {住民登錄 番號}, {電話番號, 이름}, {住民登錄 番號, 이름} 3個이다. 이들中 {住民登錄 番號}가 候補 키이며, 나머지 屬性들은 레코드를 唯一하게 識別하는데 있어서는 必要없는 屬性들이다.
- 非日次 屬性
- 非日次 屬性은 어떤 候補 키에도 나타나지 않는 屬性이다. {이름},{나이},{住民登錄 番號},{電話番號} 屬性을 가지는 테이블에서 {나이}는 非日次 屬性이다.
- 一次키
- 關係 데이터베이스(RDB)에서 關係(데이터베이스 테이블) 內의 特定 투플(熱)을 一義的으로 識別할 수 있는 키 필드. 週 키(major key)라고도 한다. 파일에서 特定 레코드를 檢索하거나 레코드들을 整列할 때 優先的으로 參照된다. 關係 內의 키 필드가 하나밖에 없을 때에는 自動的으로 그 關係의 日次 키가 된다. 그러나 하나의 關係 內에 複數의 키가 있을 때에는 그中의 하나를 日次 키로 指定해야 한다. 日次 키로 指定되지 않은 키를 代替 키(alternate key)라고 한다.
引用 資料
[
編輯
]
- ↑
Codd, E.F.
(1970年 6月).
“A Relational Model of Data for Large Shared Data Banks”
. 《
Communications of the ACM
》
13
(6): 377?387.
doi
:
10.1145/362384.362685
. 2007年 6月 12日에
原本 文書
에서 保存된 文書
. 2007年 6月 12日에 確認함
.
- ↑
Codd, E.F. "Further Normalization of the Data Base Relational Model." (Presented at Courant Computer Science Symposia Series 6, "Data Base Systems," New York City, May 24th-25th, 1971.) IBM Research Report RJ909 (August 31st, 1971). Republished in Randall J. Rustin (ed.),
Data Base Systems: Courant Computer Science Symposia Series 6
. Prentice-Hall, 1972.
- ↑
Codd, E. F. "Recent Investigations into Relational Data Base Systems." IBM Research Report RJ1385 (April 23rd, 1974). Republished in
Proc. 1974 Congress
(Stockholm, Sweden, 1974). , N.Y.: North-Holland (1974).
- ↑
C.J. Date, Hugh Darwen, Nikos Lorentzos.
Temporal Data and the Relational Model
. Morgan Kaufmann (2002), p. 176
- ↑
C.J. Date.
An Introduction to Database Systems
. Addison-Wesley (1999), p. 290
- ↑
Chris Date, for example, writes: "I believe firmly that anything less than a fully normalized design is
strongly contraindicated
... [Y]ou should
"denormalize" only as a last resort
. That is, you should back off from a fully normalized design only if all other strategies for improving performance have somehow failed to meet requirements." Date, C.J.
Database in Depth: Relational Theory for Practitioners
. O'Reilly (2005), p. 152.
- ↑
Ralph Kimball, for example, writes: "The use of normalized modeling in the data warehouse presentation area defeats the whole purpose of data warehousing, namely, intuitive and high-performance retrieval of data." Kimball, Ralph.
The Data Warehouse Toolkit, 2nd Ed.
. Wiley Computer Publishing (2002), p. 11.
- ↑
"The adoption of a relational model of data ... permits the development of a universal data sub-language based on an applied predicate calculus. A first-order predicate calculus suffices if the collection of relations is in first normal form. Such a language would provide a yardstick of linguistic power for all other proposed data languages, and would itself be a strong candidate for embedding (with appropriate syntactic modification) in a variety of host Ianguages (programming, command- or problem-oriented)." Codd,
"A Relational Model of Data for Large Shared Data Banks"
Archived
2007年 6月 12日 -
웨이백 머신
, p. 381
- ↑
Codd, E.F. Chapter 23, "Serious Flaws in SQL", in
The Relational Model for Database Management: Version 2
. Addison-Wesley (1990), p. 371-389
- ↑
Codd, E.F. "Further Normalization of the Data Base Relational Model", p. 34
- Paper: "Non First Normal Form Relations" by G. Jaeschke, H. -J Schek ; IBM Heidelberg Scientific Center. -> Paper studying normalization and denormalization operators nest and unnest as mildly described at the end of this wiki page.
같이 보기
[
編輯
]
外部 링크
[
編輯
]