Em estatistica, uma
variavel de confusao
, tambem chamada de
fator de confusao
ou
confundidor
, e uma variavel que influencia tanto a
variavel dependente
, quanto a
variavel independente
, causando uma associacao espuria. A variavel de confusao e um conceito
causal
e como tal nao pode ser descrita em termos de correlacoes ou associacoes.
[
1
]
[
2
]
[
3
]
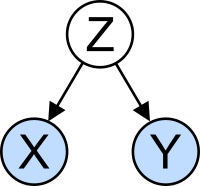 Ilustracao de um caso simples de confusao: neste modelo grafico, dada a variavel
Ilustracao de um caso simples de confusao: neste modelo grafico, dada a variavel
 , nao ha associacao entre
, nao ha associacao entre
 e
e
 . Entretanto, nao observar
criara uma associacao espuria entre
e
. Neste caso,
e a variavel de confusao. Em outras palavras,
e a causa de
e
.
. Entretanto, nao observar
criara uma associacao espuria entre
e
. Neste caso,
e a variavel de confusao. Em outras palavras,
e a causa de
e
.
A confusao e definida nos termos do modelo de geracao de dados (como na figura ao lado). Considere
uma variavel independente e
uma variavel dependente. Para estimar o efeito de
sobre
, deve-se suprimir os efeitos de variaveis estranhas que influenciam tanto
e
. Dizemos que
e
sao confundidas por uma outra variavel
sempre que
for a causa tanto de
, quanto de
.
Considere
 a probabilidade do evento
a probabilidade do evento
 sob a intervencao hipotetica
sob a intervencao hipotetica
 .
e
nao sao confundidas
se e somente se
o seguinte se aplicar:
.
e
nao sao confundidas
se e somente se
o seguinte se aplicar:

para todos os valores
e
, em que
 e a probabilidade condicional ao ver
. Intuitivamente, esta igualdade afirma que
e
nao sao confundidas sempre que a associacao observada entre elas e igual a observacao que seria medida em um experimento controlado, com
e a probabilidade condicional ao ver
. Intuitivamente, esta igualdade afirma que
e
nao sao confundidas sempre que a associacao observada entre elas e igual a observacao que seria medida em um experimento controlado, com
 aleatorizado.
aleatorizado.
A principio, a igualdade definidora
pode ser verificada a partir do modelo de geracao de dados, assumindo que temos todas as equacoes e probabilidades associadas com o modelo. Isto e feito ao simular uma intervencao
 e verificar se a probabilidade resultante de
e igual a probabilidade condicional
.
e verificar se a probabilidade resultante de
e igual a probabilidade condicional
.
Considere que um pesquisador esta tentando avaliar a efetividade da droga (
drug
)
, a partir de dados de uma populacao em que o uso da droga foi uma escolha do paciente. Os dados mostram que o genero (
gender
) do paciente (
) influencia a escolha da droga pelo paciente, assim como suas chances de recuperacao (
). Neste cenario, genero (
) confunde a relacao entre
e
, ja que
e uma causa tanto de
, quanto de
:
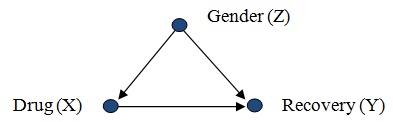 Causal diagram of Gender as common cause of Drug use and Recovery
Causal diagram of Gender as common cause of Drug use and Recovery
Temos que:

porque a quantidade observada contem informacao sobre a correlacao entre
e
e a quantidade intervencionista nao contem (ja que
nao esta correlacionada com
em um experimento aleatorizado). Certamente, deseja-se a estimativa nao viesada
, mas nos casos em que apenas os dados observados estao disponiveis, uma estimativa nao viesada so pode ser obtida ao "ajustar" para todos as variaveis de confusao, isto e, condicionando sobre seus varios valores e fazendo a media do resultado. No caso de uma unica variavel de confusao
, isto leva a seguinte "formula de ajuste":

que da uma estimativa nao viesada para o efeito causal de
sobre
. A mesma formula de ajuste pode funcionar quando ha multiplas variaveis de confusao. A escolha do conjunto
de variaveis que garantira estimativas nao viesadas deve ser feita com cautela. O criterio para uma escolha adequada e chamado de "porta dos fundos" (
backdoor
) e exige que o conjunto escolhido
"bloqueie" (ou intercepte) todo caminho de
a
que termina com uma seta em direcao a
.
[
4
]
[
1
]
Tais conjuntos sao chamados de "admissiveis pela porta dos fundos" e podem incluir variaveis que nao sao causas comuns de
e
, mas simples
proxies
.
Retornando ao exemplo do uso da droga, ja que
atende o requisito da porta dos fundos (isto e, intercepta o caminho pela porta dos fundos
 ), a formula de ajuste de porta dos fundos e valida:
), a formula de ajuste de porta dos fundos e valida:

Desta forma, pode-se prever o efeito provavel de administrar a droga a partir dos estudos observados nos quais as probabilidades condicionais que aparecem do lado direito da equacao podem ser estimadas por regressao.
Ao contrario do que se comumente acredita, adicionar covariaveis ao conjunto de ajuste
pode introduzir vies. Um tipico contraexemplo ocorre quando
e um efeito comum de
e
, um caso em que
nao e uma variavel de confusao (isto e, o conjunto vazio e admissivel pela porta dos fundos) e ajustar para
criaria um vies conhecido como vies do colisor ou paradoxo de Berkson.
[
5
]
Geralmente, a confusao pode ser controlada pelo ajuste se e somente se houver um conjunto de covariaveis observadas que satisfaz a condicao da porta dos fundos. Alem disto, se
for tal conjunto, entao, a penultima formula de ajuste acima e valida.
[
6
]
De acordo com Alfredo Morabia, a palavra "confundir" deriva do verbo do
latim medieval
"confundere", que significa "misturar", e foi provavelmente escolhida para representar a confusao entre a causa que se deseja avaliar e outras causas podem afetar o resultado e, assim, causar confusao ou ficar no caminho da avaliacao desejada.
[
7
]
O estatistico britanico
Ronald Fisher
usou a palavra "confusao" em seu livro de 1935,
The Design of Experiments
, para denotar qualquer fonte de erro em seu ideal de experimento aleatorizado.
[
8
]
De acordo com Jan P. Vandenbroucke,
[
9
]
o estatistico hungaro-americano Leslie Kish foi o primeiro a usar a palavra "confusao" no sentido moderno da palavra, para denotar "incomparabilidade" de dois ou mais grupos (por exemplo, exposto e nao exposto) em um estudo de observacao.
[
10
]
Condicoes formais que definem o que torna certos grupos "comparaveis" e outros "incomparaveis" foram posteriormente desenvolvidas em
epidemiologia
por Sander Greenland e James M. Robins,
[
11
]
usando a linguagem contrafactual do matematico polaco-americano
Jerzy Neyman
e do estatistico norte-americano Donald Rubin.
[
12
]
[
13
]
Estas foram posteriormente suplementadas pelos criterios graficos, tais como o da condicao da porta dos fundos.
[
3
]
[
4
]
Demonstrou-se que criterios graficos sao formalmente equivalentes a definicao contrafactual, mas mais transparentes aos pesquisadores que dependem de modelos de processos.
[
1
]
No caso de avaliacoes de risco que examinam a magnitude e a natureza do risco a
saude humana
, e importante controlar a confusao para isolar o efeito de um perigo particular como um componente alimenticio, um
pesticida
ou uma nova droga. Para estudos prospectivos, e dificil recrutar e avaliar voluntarios com o mesmo perfil (idade, dieta, nivel de instrucao, local de residencia, etc.) e, em estudos historicos, pode haver variabilidade semelhante. Devido a inabilidade de controlar a variabilidade de voluntarios e estudos com humanos, a confusao e um desafio particular. Por estas razoes,
experimentos
oferecem uma maneira de evitar a maioria das formas de confusao.
Em algumas disciplinas, a confusao e categorizada em diferentes tipos, Em epidemiologia, um tipo e a "confusao por indicacao", que diz respeito a confusao em
estudos observacionais
.
[
14
]
Como fatores prognosticos podem influenciar decisoes de tratamento (e enviesar estimativas de efeitos de tratamento), controlar os fatores prognosticos conhecidos pode reduzir este problema, mas e sempre possivel que um fator esquecido ou desconhecido nao seja incluido ou que os fatores interajam entre si de forma complexa. A confusao por indicacao tem sido descrita como a limitacao mais importantes de estudos observacionais. Ensaios aleatorizados nao sao afetados pela confusao por indicacao devido a
atribuicao aleatoria
.
Variaveis de confusao tambem podem ser categorizadas de acordo com suas fontes, como a escolha do instrumento de medicao (confusao operacional), as caracteristicas situacionais (confusao procedimental) ou as diferencas interindividuais (confusao pessoal):
- Uma confusao operacional pode ocorrer tanto em desenhos de pesquisa experimentais, como em nao experimentais. Este tipo de confusao ocorre quando uma medida desenhada para avaliar um
construto
particular inadvertidamente mede outra coisa tambem.
[
15
]
- Uma confusao procedimental pode ocorrer em um experimento em laboratorio ou em um quase-experimento. Este tipo de confusao ocorre quando o pesquisador erradamente permite que outra variavel mude junto com a variavel independente manipulada.
[
15
]
- Uma confusao pessoal ocorre quando dois ou mais grupos de unidades sao analisados juntos (por exemplo, trabalhadores de diferentes ocupacoes), apesar de variarem de acordo com uma outra caracteristica (observada ou nao observada) ou mais (por exemplo, genero).
[
16
]
Em outro exemplo, considere que alguem esta estudando a relacao entre ordem de nascimento (1º filho, 2º filho, etc.) e a presenca de
Sindrome de Down
na crianca. Neste cenario, a idade materna seria uma variavel de confusao:
- A idade materna mais elevada esta diretamente associada com sindrome de Down na crianca;
- A idade materna mais elevada esta diretamente associada com sindrome de Down, independentemente da ordem de nascimento (se a mae tiver o primeiro e o terceiro filho depois dos 50 anos, ha o mesmo risco);
- A idade materna esta diretamente associada com a ordem de nascimento (o segundo filho, exceto no caso de gemeos, nasce quando a mae e mais velha do que era quando o primeiro filho nasceu);
- A idade materna nao e uma consequencia da ordem de nascimento (ter um segundo filho nao muda a idade materna).
Em avaliacoes de risco, fatores como idade, genero e nivel de instrucao frequentemente afetam o
status
de saude e devem por isso ser controlados. Alem destes fatores, pesquisadores podem nao considerar ou ter acesso a dados sobre outros fatores causais. Um exemplo diz respeito ao estudo sobre consumo de tabaco na saude humana. O tabagismo, o consumo de bebidas alcoolicas e a dieta sao atividades de estilo de vida relacionadas entre si. Uma avaliacao que olha os efeitos do tabagismo, mas nao controla o consumo de alcool pode superestimar o risco de fumar.
[
17
]
O tabagismo e as variaveis de confusao sao revisadas em avaliacoes de risco ocupacional, tais como de seguranca em mineracao de carvao.
[
18
]
Quando nao ha uma grande populacao amostral de nao fumantes e abstemios em uma ocupacao particular, a avaliacao de risco pode ser enviesada na direcao de encontrar um efeito negativo sobre a saude.
Uma reducao do potencial para a ocorrencia e do efeito das variaveis de confusao pode ser obtida ao aumentar os tipos e os numeros de comparacoes realizadas em uma analise. Se as medidas ou as manipulacoes dos construtos centrais forem confundidas (isto e, se houver confusao operacional ou procedimental), a analise de subgrupo pode nao revelar problemas na analise. Adicionalmente, aumentar o numero de comparacoes pode criar outros problemas.
A
revisao por pares
e um processo que pode ajudar a reduzir instancias de confusao, seja antes da implementacao do estudo ou depois que a analise ocorreu. A revisao por pares se baseia na
expertise
coletiva no interior de uma disciplina para identificar potenciais fraquezas em desenho e analise de estudos, incluindo formas pelas quais os resultados podem estar baseados em confusao. Da mesma maneira, a replicacao pode testar a robustez das descobertas de um estudo sob condicoes alternativas de estudo ou analises alternativas (por exemplo, controlando potenciais variaveis de confusao nao identificadas no estudo inicial).
Pode ser menos provavel que efeitos de confusao ocorram e ajam de forma semelhante em momentos e lugares diferentes. Ao selecionar locais de estudo, o ambiente deve ser caracterizado em detalhe para garantir que os locais sao ecologicamente semelhantes e, consequentemente, que ha menor probabilidade de ter variaveis de confusao. A relacao entre variaveis ambientais que possivelmente confundem a analise e os parametros medidos pode ser estudada. A informacao pertinente as variaveis ambientais pode entao ser usada em modelos de locais especificos para identificar variancia residual que pode resultar de efeitos reais.
[
19
]
Dependendo do tipo de desenho de estudo em jogo, ha varias maneiras de modificar o desenho para ativamente excluir ou controlar variaveis de confusao:
[
20
]
- Estudos de caso-controle atribuem variaveis de confusao a ambos os grupos, casos e controles. Por exemplo, se alguem quiser estudar a causa do infarto do miocardio e pensar que a idade e uma provavel variavel de confusao, cada paciente de 67 anos que teve um infarto sera pareado com uma pessoa de "controle", saudavel e de 67 anos. Em estudos de caso-controle, as variaveis mais frequentemente pareadas sao idade e sexo. Estudos de caso-controle sao plausiveis apenas quando e facil encontrar controles, isto e, pessoas cujos atributos, tendo em vista todas as potenciais variaveis de confusao conhecidas, sao iguais aqueles dos pacientes do caso. Suponha que um estudo de caso-controle tenta encontrar a causa de uma doenca em uma pessoa que 1) tem 45 anos, 2) e afro-americana, 3) mora no
Alaska
, 4) joga futebol com frequencia, 5) e vegetariana e 6) trabalha com educacao. Um controle teoricamente perfeito seria uma pessoa que, alem de nao ter a doenca investigada, tem as mesmas caracteristicas do paciente, alem de nao ter nenhuma doenca que o paciente tambem nao tem ? encontrar um controle deste tipo seria uma tarefa dificilima.
- Algum grau de pareamento tambem e possivel e frequentemente realizado ao admitir apenas certos grupos etarios ou apenas um sexo na populacao do estudo, criando um coorte de pessoas que compartilham caracteristicas semelhantes e assim todos os coortes sao comparaveis no que se refere a possivel variavel de confusao. Por exemplo, se idade e sexo forem pensadas como variaveis de confusao, apenas homens com idade entre 40 e 50 anos estariam envolvidos com um estudo de coorte que avalia o risco de infarto do miocardio em coortes que sao fisicamente ativos ou inativos. Em estudos de coorte, a superexclusao de dados de entrada pode levar pesquisadores a definir muito estreitamente o conjunto de pessoas em situacoes semelhantes para as quais os pesquisadores consideram o estudo util, de forma que outras pessoas para as quais a relacao causal de fato se aplica podem perder a oportunidade de se beneficiarem das recomendacoes do estudo. Semelhantemente, a "superestratificacao" dos dados de entrada no interior de um estudo pode reduzir o tamanho da amostra em um dado estrato a ponto das generalizacoes obtidas ao observar os membros daquele estrato apenas nao serem
estatisticamente significantes
.
- Os ensaios
duplo-cegos
escondem da populacao do ensaio e dos observadores a que grupo cada um dos participantes pertence. Ao impedir os participantes de saberem se estao recebendo tratamento ou nao, o
efeito placebo
devem ser o mesmo tanto para o grupo de controle, como para o grupo de tratamento. Ao impedir os observadores de saberem a qual grupo cada participante pertence, nao deve haver vies por parte dos pesquisadores, seja tratando os grupos diferentemente, seja interpretando os resultados distintamente.
- Estudos randomizados controlados
sao um metodo em que a populacao de estudo e dividida aleatoriamente a fim de reduzir as chances de auto-selecao pelos que participam ou de vies pelos que desenharam o estudo. Antes do experimento comecar, os responsaveis pelo teste atribuirao os participantes aos seus grupos (controle, intervencao, paralelo), usando um processo de randomizacao tal como o uso de um gerador de numeros aleatorios. Por exemplo, em um estudo sobre os efeitos da atividade fisica, as conclusoes seriam menos validas se os participantes pudessem escolher se querem participar do grupo de controle que nao se exercitara ou do grupo de intervencao que praticara atividade fisica. O estudo entao capturaria outras variaveis alem de atividade fisica, tais como niveis de saude pre-experimento e motivacao para adotar habitos saudaveis. Do lado do observador, o responsavel pelo experimento pode escolher candidatos que mais provavelmente mostrarao os resultados que o estudo quer ver ou pode interpretar resultados subjetivos (uma atitude positiva, mais energica) de forma favoravel aos seus desejos.
- Como no exemplo acima, pensa-se que a atividade fisica e um comportamento que protege do infarto do miocardio e que a idade e uma possivel variavel de confusao. Na estratificacao, os dados amostrados sao estratificados por grupo etario ? isto significa que a associacao entre atividade fisica e infarto seria analisada para cada grupo etario. Se diferentes grupos etarios (ou estratos etarios) mostrarem riscos relativos muito diferente, a idade deve ser vista como uma variavel de confusao. Ha ferramentas estatisticas, como os metodos de
Mantel
?Haenszel, que respondem pela estratificacao de conjuntos de dados.
- Controlar a confusao ao medir as variaveis de confusao conhecidas e inclui-las como covariaveis e uma forma de analise multivariada. Analises multivariadas revelam muito menos informacao sobre a forca e a polaridade da variavel de confusao do que os metodos de estratificacao. Por exemplo, se a analise multivariada controla o uso de
antidepressivos
e nao estratifica antidepressivos para
triciclicos
e
inibidores seletivos de recaptacao de serotonina
, ignorara que estas duas classes de antidepressivos tem efeitos opostos sobre o infarto do miocardio e que um efeito e muito mais forte que outro.
Todos estes metodos tem suas desvantagens:
- A melhor defesa disponivel contra a possibilidade de resultados espurios devido a confusao e frequentemente dispensar os esforcos com estratificacao e, em vez disso, conduzir um estudo aleatorizado de uma amostra
suficientemente grande
tomada como um todo, de modo que todas as potenciais variaveis de confusao (conhecidas e desconhecidas) serao distribuidas por acaso ao longo dos grupos de estudo e, assim, nao correlacionadas com a variavel binaria para inclusao/exclusao em qualquer grupo.
- Em estudos randomizados controlados e duplo-cegos, os participantes nao sabem que estao recebendo tratamento simulado e que podem nao receber tratamento efetivo.
[
21
]
Ha resistencia contra estudos randomizados controlados em cirurgia porque pacientes concordariam com uma cirurgia invasiva que traz riscos sob o entendimento de que estao recebendo tratamento.
- ↑
a
b
c
Pearl, Judea (14 de setembro de 2009).
Causality
(em ingles). [S.l.]: Cambridge University Press.
ISBN
9781139643986
- ↑
VanderWeele, Tyler J.; Shpitser, Ilya (2013).
≪On the definition of a confounder≫
.
The Annals of Statistics
(em ingles).
41
(1): 196?220.
ISSN
0090-5364
.
doi
:
10.1214/12-aos1058
- ↑
a
b
Greenland, Sander; Robins, James M.; Pearl, Judea (1999).
≪Confounding and Collapsibility in Causal Inference≫
.
Statistical Science
.
14
(1): 29?46.
doi
:
10.2307/2676645
- ↑
a
b
Pearl, Judea (24 de outubro de 2011).
≪Aspects of Graphical Models Connected with Causality≫
.
Department of Statistics, UCLA
(em ingles)
- ↑
Lee, Paul H. (15 de agosto de 2014).
≪Should we adjust for a confounder if empirical and theoretical criteria yield contradictory results? A simulation study≫
.
Scientific Reports
(em ingles).
4
(1).
ISSN
2045-2322
.
doi
:
10.1038/srep06085
- ↑
Shpitser, Ilya; Pearl, Judea (2008).
≪Complete Identification Methods for the Causal Hierarchy≫
.
J. Mach. Learn. Res
.
9
: 1941?1979.
ISSN
1532-4435
- ↑
Morabia, Alfredo (1 de abril de 2011).
≪History of the modern epidemiological concept of confounding≫
.
Journal of Epidemiology & Community Health
(em ingles).
65
(4): 297?300.
ISSN
0143-005X
.
PMID
20696848
.
doi
:
10.1136/jech.2010.112565
- ↑
Fisher, Sir Ronald Aylmer (1966).
The design of experiments
(em ingles). [S.l.]: Hafner Pub. Co.
- ↑
Vandenbroucke, Jan P. (2004).
≪The history of confounding≫
. Birkhauser, Basel.
A History of Epidemiologic Methods and Concepts
(em ingles): 313?325.
doi
:
10.1007/978-3-0348-7603-2_17
- ↑
Kish, Leslie (1959).
≪Some Statistical Problems in Research Design≫
.
American Sociological Review
.
24
(3): 328?338.
doi
:
10.2307/2089381
- ↑
Greenland, Sander; Robins, James M. (1 de setembro de 1986).
≪Identifiability, Exchangeability, and Epidemiological Confounding≫
.
International Journal of Epidemiology
.
15
(3): 413?419.
ISSN
0300-5771
.
doi
:
10.1093/ije/15.3.413
- ↑
Neyman, J.; Iwaszkiewicz, K.; Kolodziejczyk, St. (1935).
≪Statistical Problems in Agricultural Experimentation≫
.
Supplement to the Journal of the Royal Statistical Society
.
2
(2): 107?180.
doi
:
10.2307/2983637
- ↑
Rubin, Donald B.
≪Estimating causal effects of treatments in randomized and nonrandomized studies.≫
.
Journal of Educational Psychology
(em ingles).
66
(5): 688?701.
doi
:
10.1037/h0037350
- ↑
Johnston, S. Claiborne (1 de agosto de 2001).
≪Identifying Confounding by Indication through Blinded Prospective Review≫
.
American Journal of Epidemiology
.
154
(3): 276?284.
ISSN
0002-9262
.
doi
:
10.1093/aje/154.3.276
- ↑
a
b
1961-, Pelham, Brett W., (2007).
Conducting research in psychology : measuring the weight of smoke
3rd ed. Australia: Thomson Wadsworth.
ISBN
0534532942
.
OCLC
70836619
- ↑
Linda,, Steg,.
Applied social psychology : understanding and managing social problems
Second ed. Cambridge: [s.n.]
ISBN
9781107044081
.
OCLC
987156961
- ↑
Tjønneland, A.; Grønbaek, M.; Stripp, C.; Overvad, K. (1999).
≪Wine intake and diet in a random sample of 48763 Danish men and women≫
.
The American Journal of Clinical Nutrition
.
69
(1): 49?54.
ISSN
0002-9165
.
PMID
9925122
- ↑
Axelson, O. (1 de agosto de 1989).
≪Confounding from smoking in occupational epidemiology.≫
.
Occupational and Environmental Medicine
(em ingles).
46
(8): 505?507.
ISSN
1351-0711
.
PMID
2673334
.
doi
:
10.1136/oem.46.8.505
- ↑
P., Calow, Peter (2009).
Handbook of Environmental Risk Assessment and Management.
Oxford: Wiley.
ISBN
9781444313192
.
OCLC
815644970
- ↑
H., Hennekens, Charles; L., Mayrent, Sherry (1987).
Epidemiology in medicine
1st ed. Boston: Little, Brown.
ISBN
0316356360
.
OCLC
16890223
- ↑
Emanuel, Ezekiel J.; Miller, Franklin G. (20 de setembro de 2001).
≪The Ethics of Placebo-Controlled Trials ? A Middle Ground≫
.
New England Journal of Medicine
.
345
(12): 915?919.
ISSN
0028-4793
.
PMID
11565527
.
doi
:
10.1056/nejm200109203451211