Computacao paralela
e uma forma de
computacao
em que varios calculos sao realizados ao mesmo tempo,
[
1
]
operando sob o principio de que grandes problemas geralmente podem ser divididos em problemas menores, que entao sao resolvidos
concorrentemente
(em paralelo). Existem diferentes formas de computacao paralela: em bit, instrucao, de dado ou de tarefa. A tecnica de paralelismo ja e empregada ha varios anos, principalmente na
computacao de alto desempenho
, mas recentemente o interesse no tema cresceu devido as limitacoes fisicas que previnem o aumento de frequencia de processamento.
[
2
]
Com o aumento da preocupacao do
consumo de energia
dos computadores, a computacao paralela se tornou o paradigma dominante nas
arquiteturas de computadores
sob forma de processadores
multinucleo
.
[
3
]
Computadores paralelos podem ser classificados de acordo com o nivel em que o hardware suporta paralelismo. Computadores com multinucleos ou
multiprocessadores
possuem multiplos elementos de processamento em somente uma maquina, enquanto
clusters
,
MPP
e
grades
usam multiplos computadores para trabalhar em uma unica tarefa. Arquiteturas paralelas especializadas as vezes sao usadas junto com processadores tradicionais, para acelerar tarefas especificas.
Programas de computador
paralelos sao mais dificeis de
programar
que sequenciais,
[
4
]
pois a concorrencia introduz diversas novas classes de
defeitos
potenciais, como a
condicao de corrida
. A
comunicacao
e a
sincronizacao
entre diferentes subtarefas e tipicamente uma das maiores barreiras para atingir grande desempenho em programas paralelos. O aumento da velocidade por resultado de paralelismo e dado pela
lei de Amdahl
.
Tradicionalmente, o software tem sido escrito para ser executado sequencialmente. Para resolver um problema, um
algoritmo
e construido e implementado como um fluxo serial de instrucoes. Tais instrucoes sao entao executadas por uma
unidade central de processamento
de um computador. Somente uma instrucao pode ser executada por vez; apos sua execucao, a proxima entao e executada.
[
5
]
Por outro lado, a computacao paralela faz uso de multiplos elementos de processamento simultaneamente para resolver um problema. Isso e possivel ao quebrar um problema em partes independentes de forma que cada elemento de processamento pode executar sua parte do algoritmo simultaneamente com outros. Os elementos de processamento podem ser diversos e incluir recursos como um unico computador com multiplos processadores, diversos computadores em
rede
, hardware especializado ou qualquer combinacao dos anteriores.
[
5
]
O aumento da frequencia de processamento foi o principal motivo para melhorar o desempenho dos computadores de meados da decada de 1980 a 2004. Em termos gerais, o
tempo de execucao
de um programa corresponde ao numero de instrucoes multiplicado pelo tempo medio de execucao por instrucao. Mantendo todo o resto constante, aumentar a frequencia de processamento de um computador reduz o tempo medio para executar uma instrucao, reduzindo entao o tempo de execucao para todos os programas que exigem alta taxa de processamento (em oposicao a operacoes em memoria.)
[
6
]
Entretanto, o
consumo de energia
de um
chip
e dado pela equacao
 , em que
, em que
 e a potencia desempenhada pelo processador,
e a potencia desempenhada pelo processador,
 e a
capacitancia
sendo trocada por ciclo de
clock
(proporcional ao numero de
transistores
cujas entradas mudam),
e a
capacitancia
sendo trocada por ciclo de
clock
(proporcional ao numero de
transistores
cujas entradas mudam),
 e a
tensao
e
e a
tensao
e
 e a frequencia do processador (ciclos por segundo). A energia total gasta e obtida por
e a frequencia do processador (ciclos por segundo). A energia total gasta e obtida por
 =
=
 em que
em que
 e o tempo em que o processador ficou ligado.
[
7
]
Aumentar a frequencia significa aumentar a quantidade de energia usada em um processador. Em
2004
, esse aumento de consumo levou a
Intel
a cancelar seu modelos de processadores Tejas e
Jayhawk
, geralmente citado como o fim da frequencia de processamento como paradigma predominante nas arquiteturas de computador.
[
8
]
e o tempo em que o processador ficou ligado.
[
7
]
Aumentar a frequencia significa aumentar a quantidade de energia usada em um processador. Em
2004
, esse aumento de consumo levou a
Intel
a cancelar seu modelos de processadores Tejas e
Jayhawk
, geralmente citado como o fim da frequencia de processamento como paradigma predominante nas arquiteturas de computador.
[
8
]
A
lei de Moore
e a observacao empirica de que a densidade de transistores em um microprocessador dobra a cada 18 a 24 meses.
[
9
]
Apesar do consumo de energia e de repetidas previsoes sobre seu fim, ela ainda vale. Com o fim do aumento da frequencia de processamento, esses transistores adicionais podem ser usados para adicionar hardware a computacao paralela.
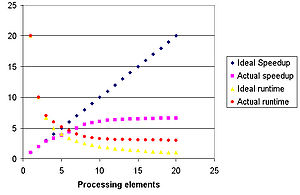 O tempo de execucao e o aumento de velocidade de um programa com paralelismo. A curva azul ilustra o aumento linear que um programa teria no caso ideal, enquanto a curva roxa indica o aumento real. Da mesma forma, a curva amarela indica o tempo de execucao no caso ideal (uma
assimptota
tendendo a zero), enquanto a curva vermelha indica o tempo de execucao real (uma assimptota tendendo a um valor acima de zero)
[
10
]
O tempo de execucao e o aumento de velocidade de um programa com paralelismo. A curva azul ilustra o aumento linear que um programa teria no caso ideal, enquanto a curva roxa indica o aumento real. Da mesma forma, a curva amarela indica o tempo de execucao no caso ideal (uma
assimptota
tendendo a zero), enquanto a curva vermelha indica o tempo de execucao real (uma assimptota tendendo a um valor acima de zero)
[
10
]
Teoricamente, o aumento de velocidade com o paralelismo deveria ser linear, de forma que dobrando a quantidade de elementos de processamento, reduz-se pela metade o tempo de execucao. Entretanto, muitos poucos algoritmos paralelos atingem essa situacao ideal. A maioria deles possui aumento de velocidade quase linear para poucos elementos de processamento, tendendo a um valor constante para uma grande quantidade de elementos.
O aumento de velocidade potencial de um algoritmo em uma plataforma de computacao paralela e dado pela
lei de Amdahl
, formulada por
Gene Amdahl
na decada de 1960.
[
11
]
Ela afirma que uma pequena porcao do programa que nao pode ser paralelizada limitara o aumento de velocidade geral disponivel com o paralelismo. Qualquer grande problema da matematica ou da engenharia tipicamente consistira de diversas partes paralelizaveis e diversas partes sequenciais. A relacao entre os dois e dada pela equacao:

em que
 e o aumento de velocidade do programa e
e a fracao paralelizavel. Se a porcao sequencial de um programa representa 10% do tempo de execucao, nao se pode obter mais que dez vezes de aumento de velocidade, independente de quantos processadores sao adicionados. Isso limita a utilidade da adicao de mais unidades paralelas de execucao.
e o aumento de velocidade do programa e
e a fracao paralelizavel. Se a porcao sequencial de um programa representa 10% do tempo de execucao, nao se pode obter mais que dez vezes de aumento de velocidade, independente de quantos processadores sao adicionados. Isso limita a utilidade da adicao de mais unidades paralelas de execucao.
A
lei de Gustafson
esta realacionada com a de Amdahl. Ela pode ser formulada como:
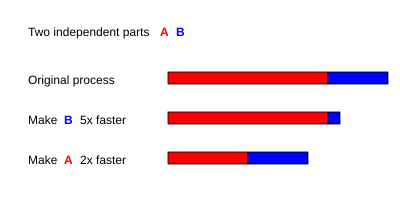 Representacao grafica da
lei de Amdahl
. Assumindo que uma tarefa possui duas partes independentes, A e B. B ocupa cerca de 25% de todo o tempo de execucao. Com esforco, um programador pode tornar tal tarefa cinco vezes mais rapida, mas isso reduz somente um pouco o tempo total da execucao. Em contraste, com menos esforco pode-se tornar a parte A duas vezes mais rapida. Isso tornara a computacao muito mais rapida que otimizar a parte B, ainda que B resulte em maior aumento de velocidade.
[
12
]
Representacao grafica da
lei de Amdahl
. Assumindo que uma tarefa possui duas partes independentes, A e B. B ocupa cerca de 25% de todo o tempo de execucao. Com esforco, um programador pode tornar tal tarefa cinco vezes mais rapida, mas isso reduz somente um pouco o tempo total da execucao. Em contraste, com menos esforco pode-se tornar a parte A duas vezes mais rapida. Isso tornara a computacao muito mais rapida que otimizar a parte B, ainda que B resulte em maior aumento de velocidade.
[
12
]

em que
e o numero de processadores,
e o aumento de velocidade e
 e a parte nao paralelizavel do processo.
[
13
]
A lei de Amdahl assume um tamanho de problema fixo e que o tamanho da secao sequencial e independente do numero de processadores, enquanto a lei de Gustafson nao parte dessas premissas.
e a parte nao paralelizavel do processo.
[
13
]
A lei de Amdahl assume um tamanho de problema fixo e que o tamanho da secao sequencial e independente do numero de processadores, enquanto a lei de Gustafson nao parte dessas premissas.
Entender a
dependencia de dados
e fundamental na implementacao de algoritmos paralelos. Nenhum programa pode rodar mais rapido que a maior cadeia de calculos dependentes (conhecido como caminho critico), ja que o calculo depende do calculo anterior da cadeia, sendo executado sequencialmente. Entretanto, a maioria dos algoritmos nao consiste de somente uma longa cadeia de calculos dependentes; geralmente ha oportunidades para executar calculos independentes em paralelo.
Assumindo os fragmentos de programa
 e
e
 . As condicoes de Bernstein
[
14
]
descrevem quando os dois fragmentos sao independentes e podem ser executados em paralelo. Para
, assume-se que
. As condicoes de Bernstein
[
14
]
descrevem quando os dois fragmentos sao independentes e podem ser executados em paralelo. Para
, assume-se que
 sao todas as variaveis de entrada e
sao todas as variaveis de entrada e
 todas as variaveis de saida, e o mesmo para
.
e
sao independentes se:
todas as variaveis de saida, e o mesmo para
.
e
sao independentes se:



A violacao da primeira condicao introduz uma dependencia de fluxo, correspondendo ao primeiro fragmento produzindo um resultado usado pelo segundo. A segunda condicao representa a antidependencia, quando o primeiro fragmento sobrescreve uma variavel necessaria pela segunda expressao. A terceira condicao e a dependencia de saida. Quando duas variaveis escrevem no mesmo local, a saida final deve vir do segundo fragmento.
[
15
]
Considerando as seguintes
subrotinas
, que demonstram diferentes tipos de dependencias:
1: ROTINA dep(a, b)
2: c ← a · b
3: d ← 2 · c
4: FIM ROTINA
A operacao 3 de
Dep(a, b)
nao pode ser executada antes ou paralelamente a operacao 2 porque a operacao 3 usa o resultado da operacao 2. Essa e uma violacao da primeira condicao, introduzindo a dependencia de fluxo.
1: ROTINA no_dep(a, b)
2: c ← a · b
3: d ← 2 · b
4: e ← a + b
5: FIM ROTINA
Neste exemplo, nao ha dependencias entre as instrucoes, entao elas podem ser executadas em paralelo.
As condicoes de Bernstein nao permitem que a memoria seja compartilhada por diferentes processos. Para isso, e necessaria alguma forma de assegurar a ordem de acesso ao recurso, como
semaforos
, barreiras ou alguma outra forma de
sincronizacao
.
Condicoes de corrida, exclusao mutua e lentidao paralela
[
editar
|
editar codigo-fonte
]
Subtarefas de um programa paralelo sao frequentemente chamadas
threads
. Algumas arquiteturas paralelas usam versoes mais leves e menores de
threads
conhecidas como
fibras
, enquanto outras usam versoes maiores chamadas
processos
. Entretanto, as
threads
sao geralmente aceitas como o termo generico para as subtarefas. Pelo menos uma
variavel
do sistema geralmente e compartilhada por mais de uma
thread
. As instrucoes entre dois programas podem ser escalonadas em qualquer ordem. Por exemplo, considerando o seguinte programa:
| Thread A
|
Thread B
|
| 1A: Ler a variavel V
|
1B: Ler a variavel V
|
| 2A: Adicionar 1 a variavel V
|
2B: Adicionar 1 a variavel V
|
| 3A: Escrever o resultado na variavel V
|
3B: Escrever o resultado na variavel V
|
Se a instrucao 1B e executada entre 1A e 3A, ou se a instrucao 1A e executada entre 1B e 3B, o programa produzira dados incorretos, por conta de um problema conhecido como
condicao de corrida
. O programador deve usar um bloqueio de acesso para prover
exclusao mutua
. Tal bloqueio e uma construcao de uma linguagem de programacao que permite a uma
thread
ter total controle de uma variavel, prevenindo que outras
threads
acessem a mesma regiao de memoria ate que se faca o desbloqueio. A
thread
que detem o bloqueio e livre para executar sua
regiao critica
. Para garantir a execucao correta do programa, deve-se reescreve-lo usando bloqueios:
| Thread A
|
Thread B
|
| 1A: Bloquear a variavel V
|
1B: Bloquear a variavel V
|
| 2A: Ler a variavel V
|
2B: Ler a variavel V
|
| 3A: Adicionar 1 a variavel V
|
3B: Adicionar 1 a variavel V
|
| 4A: Escrever o resultado na variavel V
|
4B: Escrever o resultado na variavel V
|
| 5A: Desbloquear a variavel V
|
5B: Desbloquear a variavel V
|
Uma das duas
threads
conseguira bloquear a variavel, enquanto a outra ficara esperando impossibilitada de continuar sua execucao ate que o desbloqueio seja feito. Ainda que tal bloqueio garante a execucao correta do programa, ele pode tornar o programa consideravelmente mais lento.
Bloquear multiplas variaveis usando bloqueios
nao atomicos
introduz a possibilidade de
deadlock
. Um bloqueio atomico bloqueia diversas variaveis simultaneamente. Nao podendo bloquear qualquer uma delas, todo o bloqueio falha. Se duas
threads
precisam bloquear as mesmas duas variaveis usando bloqueios nao atomicos, e possivel que cada uma das
threads
bloqueie uma variavel distinta. Nesse caso, nenhuma
thread
pode continuar e o
deadlock
ocorre.
Nem todo paralelismo resulta em aumento de velocidade. Geralmente, como uma tarefa e dividida em diversas
threads
, tais
threads
gastam determinado tempo comunicando-se com outras. Eventualmente, o
overhead
da comunicacao domina o tempo gasto para resolver o problema. Nesse caso, quanto mais paralelismo e feito, mais lento e o tempo total de execucao, um efeito conhecido como lentidao paralela.
 Leslie Lamport
definiu o conceito de consistencia sequencial. Ele tambem e conhecido por ter criado o
LaTeX
Leslie Lamport
definiu o conceito de consistencia sequencial. Ele tambem e conhecido por ter criado o
LaTeX
Linguagens de programacao e computadores paralelos devem ter um
modelo de consistencia
, tambem conhecido como modelo de memoria, que define as regras de execucao das operacoes em
memoria
e como os resultados sao produzidos.
Um dos primeiros modelos de consistencia foi a consistencia sequencial de
Leslie Lamport
. Tal modelo e a propriedade de que a execucao de um programa paralelo produz o mesmo resultado que um programa sequencial. Especificamente, um programa e sequencialmente consistente se "… os resultados de qualquer de suas execucoes e o mesmo se as operacoes de todos os processadores forem executadas em alguma ordem sequencial, e as operacoes de cada processador aparecem nessa sequencia na ordem especificada pelo programa".
[
16
]
Matematicamente, tais modelos podem ser representados de diversas formas. Introduzidas por
Carl Adam Petri
em sua tese de doutorado em 1962, as
redes de Petri
foram uma primeira abordagem para codificar as regras de modelos de consistencia. Posteriormente a teoria de fluxos de dados foi construida, e
arquiteturas de fluxo de dado
foram criadas para implementar fisicamente as ideias da teoria de fluxo de dado. A partir do final da decada de 1970,
algebras de processo
como calculo de sistemas de comunicacao e
processos de comunicacao serial
foram desenvolvidos para permitir a modelagem algebrica de sistemas compostos por componentes que interagem. Adicoes mais recentes a familia, como o
calculo pi
, adicionaram a capacidade de modelar topologias dinamicas. Logicas como o TLA+ e modelos matematicos como
traces
tambem foram desenvolvidos par descrever o comportamento de sistemas concorrentes.
Michael J. Flynn
criou um dos primeiros sistemas de classificacao para computadores e programas paralelos e sequenciais, atualmente conhecida como
taxonomia de Flynn
. O cientista classificou os programas e computadores por quantidade de fluxos de instrucoes, e por quantidade de dados usadas por tais instrucoes.
A classificacao SISD equivale a um programa inteiramente sequencial, e a classificacao
SIMD
e analoga a fazer a mesma operacao repetidamente por um grande conjunto de dados. A classificacao MISD raramente e usada, ja os programas MIMD sao os programas paralelos mais comuns.
A partir do advento da tecnologia de fabricacao de chip
VLSI
na decada de 1970 ate cerca de 1986, o aumento da velocidade na arquitetura de computador era obtido dobrando-se o tamanho da
palavra
, a quantidade de informacao que o processador pode executar por ciclo.
[
17
]
Aumentar o tamanho da palavra reduz a quantidade de instrucoes que um processador deve executar para realizar uma operacao em variaveis cujo tamanho e maior do que o da palavra.
Historicamente, microprocessadores de quatro bits foram substituidos por oito, entao para dezesseis e entao para trinta e dois. A partir de entao, o padrao
32-bit
se manteve na computacao de uso geral por duas decadas. Cerca de 2003, a arquitetura
64-bit
comecou a ganhar mais espaco.
 Um
pipeline
canonico de cinco estagios em uma maquina
RISC
(IF =
Instruction Fetch
, ID =
Instruction Decode
, EX =
Execute
, MEM =
Memory access
, WB =
Register write back
)
Um
pipeline
canonico de cinco estagios em uma maquina
RISC
(IF =
Instruction Fetch
, ID =
Instruction Decode
, EX =
Execute
, MEM =
Memory access
, WB =
Register write back
)
Em sua essencia, um programa de computador e um fluxo de instrucoes executadas por um processador. Tais instrucoes podem ser reordenadas e combinadas em grupos que entao sao executados em paralelo sem mudar o resultado do programa. Isso e conhecido por paralelismo em instrucao. Avancos nessa tecnica dominaram a arquitetura de computador de meados da decada de 1980 ate meados da decada de 1990.
[
18
]
Processadores modernos possuem
pipeline
com multiplos estagios. Cada estagio corresponde a uma acao diferente que o processador executa em determinada instrucao; um processador com um
pipeline
de N estagios pode ter ate N diferentes instrucoes em diferentes estagios de execucao. O exemplo canonico e o processador RISC, com cinco estagios:
instruction fetch
,
decode
,
execute
,
memory access
e
write back
. O processador
Pentium 4
possui um
pipeline
de 35 estagios.
[
19
]
 Um processador
superescalar
com
pipeline
de cinco estagios, capaz de lidar com duas instrucoes por ciclo. Ele pode ter duas instrucoes em cada estagio, em um totoal de dez instrucoes sendo executadas simultaneamente
Um processador
superescalar
com
pipeline
de cinco estagios, capaz de lidar com duas instrucoes por ciclo. Ele pode ter duas instrucoes em cada estagio, em um totoal de dez instrucoes sendo executadas simultaneamente
Alem do paralelismo em instrucao obtido com o
pipeline
, alguns processadores podem lidar com mais de uma instrucao por vez. Sao conhecidos como processadores
superescalares
. As instrucoes podem ser agrupadas somente se nao ha dependencia de dados entre elas. O
algoritmo de marcador
e o
algoritmo de Tomasulo
sao duas das tecnicas mais usadas para implementar reordenacao de execucao e paralelismo em instrucao.
O paralelismo em dado e inerente a
lacos de repeticao
, focando em distribuir o dado por diferentes nos computacionais para serem processados em paralelo. Diversas aplicacoes cientificas e de engenharia apresentam esse tipo de paralelismo.
Uma dependencia por laco e a dependencia de uma iteracao do laco com a saida de uma ou mais iteracoes anteriores, uma situacao que impossibilita a paralelizacao de lacos. Por exemplo, considerando o seguinte
pseudocodigo
que calcula os primeiros
numeros de Fibonacci
:
1: anterior2 ← 0
2: anterior1 ← 1
3: atual ← 1
4: FACA:
5: atual ← anterior1 + anterior2
6: anterior2 ← anterior1
7: anterior1 ← atual
8: ENQUANTO (atual < 10)
Esse laco nao pode ser paralelizado porque
atual
depende de si (
anterior1
) e
anterior2
, que sao calculados em cada iteracao. Como cada iteracao depende do resultado da anterior, elas nao podem ser realizadas em paralelo. Com o aumento do tamanho de um problema, geralmente aumenta-se a quantidade de paralelismo em dado disponivel.
[
20
]
Paralelismo em tarefa e a caracteristica de um programa paralelo em que diferentes calculos sao realizados no mesmo ou em diferentes conjuntos de dados.
[
21
]
Isso contrasta com o paralelismo em dado, em que o mesmo calculo e feito em diferentes conjuntos de dados. Paralelismo em tarefa geralmente nao e escalavel com o tamanho do problema.
[
20
]
A memoria principal de um computador paralelo e
compartilhada
(compartilhada entre os elementos de processamento num unico
espaco de enderecamento
) ou
distribuida
(cada elemento de processamento possui seu proprio espaco de enderecamento).
[
22
]
Memoria distribuida se refere ao fato da memoria ser logicamente distribuido, mas frequentemente isso tambem implica na distribuicao fisica. A memoria distribuida e compartilhada e uma combinacao das duas abordagens, em que cada elemento de processamento possui sua memoria local e acessa a memoria de outros processadores remotos. Acesso a memoria local e geralmente mais rapido que acesso a memoria remota.
Arquiteturas de computador
em que cada elemento da memoria principal pode ser acessado com a mesma latencia e banda sao conhecidas como sistemas de
Acesso a Memoria Unificado
. Isso geralmente e feito por um sistema com somente memoria compartilhada. Um sistema que nao possui tal propriedade e conhecido como sistema de Acesso a Memoria Nao-Unificado, o que inclui sistemas que utilizam memoria distribuida.
Computadores fazem uso de
cache
, memorias pequenas e rapidas localizadas proximo ao
processador
, e que armazenam copias temporarias de valores e memoria. Computadores paralelos possuem dificuldades com caches que podem armazenar o mesmo valor em mais de um local, com a possibilidade de execucao incorreta do programa. Tais sistemas existem um mecanismo de
coerencia de cache
, que asseguram a execucao correta. Desenvolver mecanismos de coerencia de cache de alto desempenho e um problema muito dificil na arquitetura de computador. Como resultado, arquiteturas de memoria compartilhada nao
escalonam
tao bem quanto sistemas distribuidos.
[
22
]
A comunicacao dos processadores entre si e com as memorias podem ser implementadas em hardware de varias formas, incluindo por memoria compartilhada, barramento compartilhado ou uma rede interconectada. Para o ultimo caso, deve haver uma forma de
roteamento
para permitir a troca de mensagens entre nos que nao estao diretamente conectados.
Linguagens de programacao
,
bibliotecas
,
API
e modelos foram criados para
programar
computadores paralelos. Geralmente divide-se em classes de plataformas, baseadas nas premissas sobre a arquitetura de memoria usada, incluindo memoria compartilhada, memoria distribuida ou memoria compartilhada e distribuida. Linguagens de programacao de memoria compartilhada se comunicam ao manipularem
variaveis
de
memoria compartilhada
. Exemplos de uso do modelo incluem
POSIX Threads
e
OpenMP
. Ja a memoria distribuida faz uso de
troca de mensagens
. Exemplos de uso do modelo incluem
Message Passing Interface
. Um conceito usado em programacao paralela e o
valor futuro
, quando uma parte do programa promete processar dados para outra parte de um programa em um momento futuro.
A habilidade de um
compilador
realizar paralelismo automatico de um programa sequencial e um dos assuntos mais estudados no campo de computacao paralela. Entretanto, apesar de decadas de trabalho por pesquisadores de compiladores, pouco sucesso se teve na area.
[
23
]
Linguagens de programacao paralelas de amplo uso continuam explicitas, isto e, requerendo a programacao paralela propriamente dita; ou no maximo parcialmente implicitas, em que o programador fornece ao compilador
diretivas
para o paralelismo.
Com o desenvolvimento de computadores paralelos, torna-se mais viavel resolver problemas anteriormente muito demorados para se executar. A computacao paralela e usada em diversos campos, da
bioinformatica
(para o
enovelamento de proteinas
) a
economia
(para simulacoes de
matematica financeira
). Tipos comuns de problemas encontrados em aplicacoes de computacao paralela sao:
[
24
]
Referencias
- ↑
Almasi, G.S. e A. Gottlieb (1989).
Highly Parallel Computing
. Benjamin-Cummings, Redwood City, CA.
- ↑
S.V. Adve et al. (Novembro de 2008).
"Parallel Computing Research at Illinois: The UPCRC Agenda"
Arquivado em
9 de dezembro de 2008, no
Wayback Machine
.. Parallel@Illinois, Universidade de Illinois.
- ↑
Asanovic, Krste et al. (18 de dezembro de 2006).
"The Landscape of Parallel Computing Research: A View from Berkeley"
. Universidade da California, Berkeley. Technical Report UCB/EECS-2006-183.
- ↑
Patterson, David A. e John L. Hennessy (1998).
Computer Organization and Design
, Second Edition, Morgan Kaufmann Publishers, p. 715.
ISBN
1558604286
.
- ↑
a
b
Barney, Blaise.
≪Introduction to Parallel Computing≫
. Lawrence Livermore National Laboratory
. Consultado em 9 de novembro de 2007
- ↑
Hennessy, John L. e David A. Patterson (2002).
Computer Architecture: A Quantitative Approach
. 3ª edicao, Morgan Kaufmann, p. 43.
ISBN
1558607242
.
- ↑
Rabaey, J. M. (1996).
Digital Integrated Circuits
. Prentice Hall, p. 235.
ISBN
0131786091
.
- ↑
Flynn, Laurie J.
"Intel Halts Development of 2 New Microprocessors"
.
The New York Times
, 8 de maio de 2004.
- ↑
Gordon E. Moore (1965).
≪Cramming more components onto integrated circuits≫
(PDF)
.
Electronics Magazine
. Consultado em 4 de janeiro de 2009
. Arquivado do
original
(PDF)
em 18 de fevereiro de 2008
- ↑
Traducao do texto da imagemEixo da abcissa: elementos de processamentoLegenda azul: aumento de velocidade idealLegenda roxa: aumento de velocidade realLegenda amarela: tempo de execucao idealLegenda vermelha: tempo de execucao real
- ↑
Amdahl, G. (abril de 1967) "The validity of the single processor approach to achieving large-scale computing capabilities". Em
Proceedings of AFIPS Spring Joint Computer Conference
, Atlantic City, N.J., AFIPS Press, pp. 483?85.
- ↑
Traducao do texto da imagemDuas partes independentes A BPrimeira barra: processo originalTornar B 5x mais rapidaTornar A 2x mais rapida
- ↑
Reevaluating Amdahl's Law
Arquivado em
27 de setembro de 2007, no
Wayback Machine
. (1988).
Communications of the ACM
31(5), pp. 532?33.
- ↑
Bernstein, A. J. (Outubro de 1966). "Program Analysis for Parallel Processing', IEEE Trans. em Electronic Computers". EC-15, pp. 757?62.
- ↑
Roosta, Seyed H. (2000). "Parallel processing and parallel algorithms: theory and computation". Springer, p. 114.
ISBN
0387987169
.
- ↑
Lamport, Leslie (September 1979). "How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs", IEEE Transactions on Computers, C-28,9, pp. 690?91.
- ↑
Culler, David E.; Jaswinder Pal Singh e Anoop Gupta (1999).
Parallel Computer Architecture - A Hardware/Software Approach
. Morgan Kaufmann Publishers, p. 15.
ISBN
1558603433
.
- ↑
Culler et al. p. 15.
- ↑
Patt, Yale
(Abril de 2004). "
The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them?
Arquivado em
14 de abril de 2008, no
Wayback Machine
. (wmv). Palestra na
Universidade Carnegie Mellon
.
- ↑
a
b
Culler et al. p. 125.
- ↑
Culler et al. p. 124.
- ↑
a
b
Patterson and Hennessy, p. 713.
- ↑
Shen, John Paul e Mikko H. Lipasti (2005).
Modern Processor Design: Fundamentals of Superscalar Processors
. McGraw-Hill Professional. p. 561.
ISBN
0070570647
.
- ↑
Asanovic, Krste, et al. (18 de dezembro de 2006).
The Landscape of Parallel Computing Research: A View from Berkeley
. Universidade da California, Berkeley. Technical Report UCB/EECS-2006-183. Ver tabelas nas paginas 17-19.