A
analise de dados
e um processo de inspecao, limpeza, transformacao e
modelagem de
dados
com o objetivo de descobrir informacoes uteis, informar conclusoes e apoiar a tomada de decisoes. A analise de dados tem multiplas facetas e abordagens, abrangendo diversas tecnicas sob uma variedade de nomes, e e usada em diferentes dominios dos negocios, ciencias e
ciencias sociais
. No mundo dos negocios de hoje, a analise de dados desempenha um papel tornando a tomada de decisoes mais cientificas e ajudando as empresas a operar com mais eficacia.
[
1
]
A
mineracao de dados
e uma tecnica de analise de dados especifica que se concentra na modelagem estatistica e na descoberta de conhecimento para fins preditivos em vez de puramente descritivos, enquanto a
inteligencia de negocios
cobre analises de dados que dependem fortemente da agregacao, com foco principalmente nas informacoes de negocios.
[
2
]
Em aplicativos estatisticos, a analise de dados pode ser dividida em
estatistica descritiva
,
analise exploratoria de dados
(AED) e
analise confirmatoria de dados
(ACD). A AED se concentra em descobrir novas caracteristicas nos dados, enquanto a ACD se concentra em confirmar ou refutar
hipoteses
existentes. A analise preditiva se concentra na aplicacao de modelos estatisticos para previsao ou classificacao preditiva, enquanto a
analise de texto
aplica tecnicas estatisticas, linguisticas e estruturais para extrair e classificar informacoes de fontes textuais, um tipo de dados nao estruturados. Todos os itens acima sao variedades de analise de dados.
A integracao de dados e um precursor da analise de dados, e a analise de dados esta intimamente ligada a
visualizacao
e disseminacao de dados.
[
3
]
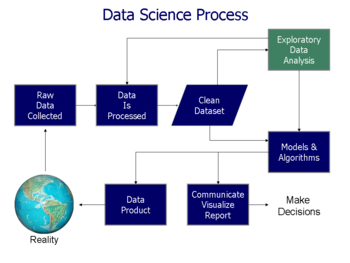 Fluxograma do processo de ciencia de dados de
Doing Data Science
, de Schutt & O'Neil (2013)
Fluxograma do processo de ciencia de dados de
Doing Data Science
, de Schutt & O'Neil (2013)
A
analise
refere-se a divisao de um todo em seus componentes separados para exame individual. A
analise de dados
e um processo de obtencao de
dados brutos
, e posterior conversao dos mesmos em informacoes uteis para a tomada de decisao dos usuarios. Os
dados
sao coletados e analisados para responder a perguntas, testar hipoteses ou refutar hipoteses.
[
4
]
O estatistico
John Tukey
definiu a analise de dados em 1961, como:
"Procedimentos para a analise de dados, tecnicas de interpretacao dos resultados de tais procedimentos, formas de planejar a coleta de dados para tornar sua analise mais facil, mais precisa ou mais exata, e todos os mecanismos e resultados das estatisticas (matematicas) que se aplicam a analise de dados."
[
5
]
Existem varias fases que podem ser distinguidas, descritas a seguir. As fases sao
iterativas
, em que o feedback das fases posteriores pode resultar em trabalho adicional nas fases anteriores.
[
6
]
A
estrutura CRISP
, usada na
mineracao de dados
, tem etapas semelhantes.
Os dados sao necessarios como entradas para a analise, que e especificada com base nos requisitos daqueles que dirigem a analise ou dos clientes (que usarao o produto acabado da analise). O tipo geral de entidade sobre a qual os dados serao coletados e chamado de unidade experimental (por exemplo, uma pessoa ou populacao de pessoas). Variaveis especificas relacionadas a uma populacao (por exemplo, idade e renda) podem ser especificadas e obtidas. Os dados podem ser numericos ou categoricos (ou seja, um rotulo de texto para numeros).
[
6
]
Os dados sao coletados de varias fontes. Os requisitos podem ser comunicados por analistas aos custodiantes dos dados; como o
pessoal de tecnologia da informacao
dentro de uma organizacao. Os dados tambem podem ser coletados de sensores no ambiente, incluindo cameras de trafego, satelites, dispositivos de gravacao, etc. Tambem pode ser obtido por meio de entrevistas, downloads de fontes online ou leitura de documentacao.
[
6
]
 As fases do ciclo de inteligencia usadas para converter informacoes brutas em inteligencia ou conhecimento acionavel sao conceitualmente semelhantes as fases da analise de dados
As fases do ciclo de inteligencia usadas para converter informacoes brutas em inteligencia ou conhecimento acionavel sao conceitualmente semelhantes as fases da analise de dados
Os dados, quando obtidos inicialmente, devem ser processados ou organizados para analise. Por exemplo, isso pode envolver a colocacao de dados em linhas e colunas em um formato de tabela (
conhecido como
dados estruturados) para analise posterior, geralmente por meio do uso de softwares estatisticos ou de planilhas.
[
6
]
Uma vez processados e organizados, os dados podem estar incompletos, conter duplicatas ou conter erros. A necessidade de
limpeza de dados
, surgira de problemas na forma como os dados sao inseridos e armazenados. A limpeza de dados e o processo de prevencao e correcao desses erros. Tarefas comuns incluem correspondencia de registros, identificacao de dados imprecisos, qualidade geral dos dados existentes, desduplicacao e segmentacao de colunas.
[
7
]
Esses problemas de dados tambem podem ser identificados por meio de uma variedade de tecnicas analiticas. Por exemplo, com informacoes financeiras, os totais para variaveis especificas podem ser comparados com numeros publicados separadamente, que se acredita serem confiaveis.
[
8
]
Valores incomuns, acima ou abaixo de limites predeterminados, tambem podem ser revisados. Existem varios tipos de limpeza de dados, que dependem do tipo de dados no conjunto; estes podem ser numeros de telefone, enderecos de e-mail, empregadores ou outros valores. Os metodos de dados quantitativos para deteccao de valores discrepantes podem ser usados para eliminar dados que parecem ter uma maior probabilidade de terem sido inseridos incorretamente. Os corretores ortograficos de dados textuais podem ser usados para diminuir a quantidade de palavras digitadas incorretamente, no entanto, e mais dificil dizer se as proprias palavras estao corretas.
[
9
]
Uma vez que os conjuntos de dados estejam limpos, eles podem ser analisados. Os analistas podem aplicar uma variedade de tecnicas, conhecidas como
analise exploratoria de dados
, para comecar a entender as mensagens contidas nos dados obtidos. O processo de exploracao de dados pode resultar em limpeza adicional dos dados ou em solicitacoes de dados adicionais; portanto, a inicializacao das
fases iterativas
mencionadas no paragrafo inicial desta secao. As
estatisticas descritivas
, como a media ou a mediana, podem ser geradas para auxiliar na compreensao dos dados. A
visualizacao dos dados
tambem e uma tecnica utilizada, na qual o analista pode examinar os dados em formato grafico para obter
insights
adicionais sobre as mensagens contidas nos dados.
[
6
]
Podem ser aplicadas
formulas
ou
modelos
matematicos
(conhecidos como
algoritmos
) aos dados para identificar relacoes entre as variaveis; por exemplo, usando
correlacao
ou
causalidade
. Em termos gerais, os modelos podem ser desenvolvidos para avaliar uma variavel especifica com base em outras variaveis contidas no conjunto de dados, com algum
erro residual
dependendo da precisao do modelo implementado (por exemplo, Dados = Modelo + Erro).
[
4
]
A
estatistica inferencial
inclui a utilizacao de tecnicas que medem as relacoes entre variaveis especificas. Por exemplo, a
analise de regressao
pode ser usada para modelar se uma mudanca nas propagandas (
variavel independente X
) fornece uma explicacao para a variacao nas vendas (
variavel dependente Y
). Em termos matematicos,
Y
(vendas) e uma funcao de
X
(publicidade). Isso pode ser descrito como (
Y
=
aX
+
b
+ erro), onde o modelo e projetado de tal forma que
(a
) e
(b
) minimizem o erro quando o modelo preve
Y
para um determinado intervalo de valores de
X
. Os analistas tambem podem tentar construir modelos descritivos dos dados, com o objetivo de simplificar a analise e comunicar os resultados.
[
4
]
Um
produto de dados
e um aplicativo de computador que recebe
entradas de dados
e gera
saidas
, devolvendo-os ao ambiente. Ele pode se basear em um modelo ou algoritmo. Por exemplo, um aplicativo que analisa dados sobre o historico de compras de um cliente e usa os resultados para recomendar outras compras que o cliente possa gostar.
[
6
]
 Visualizacao de dados
para entender os resultados de uma analise de dados.
[
10
]
Visualizacao de dados
para entender os resultados de uma analise de dados.
[
10
]
Uma vez que os dados sao analisados, eles podem ser apresentados em varios formatos para que os usuarios da analise apoiem seus requisitos. Os usuarios podem ter
feedback
, o que resulta em analises adicionais. Como tal, grande parte do ciclo analitico e iterativo.
[
6
]
Ao determinar como comunicar os resultados, o analista pode considerar a implementacao de uma variedade de tecnicas de visualizacao de dados, para ajudar a comunicar a mensagem ao publico de forma clara e eficiente. A visualizacao de dados usa
telas de informacoes
(graficos, como tabelas e graficos) para ajudar a comunicar as mensagens principais contidas nos dados. As
tabelas
sao uma ferramenta valiosa, pois permitem a um usuario consultar e focar em numeros especificos; enquanto graficos (por exemplo, graficos de barras ou de linhas), podem ajudar a explicar as mensagens quantitativas contidas nos dados.
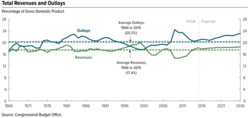 Uma serie temporal ilustrada com um grafico de linhas que demonstra as tendencias dos gastos e receitas federais dos EUA ao longo do tempo
Uma serie temporal ilustrada com um grafico de linhas que demonstra as tendencias dos gastos e receitas federais dos EUA ao longo do tempo
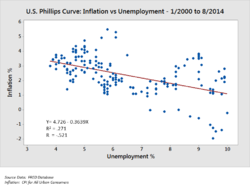 Um grafico de dispersao que ilustra a correlacao entre duas variaveis (inflacao e desemprego) medidas em pontos no tempo
Um grafico de dispersao que ilustra a correlacao entre duas variaveis (inflacao e desemprego) medidas em pontos no tempo
Stephen Few descreveu oito tipos de mensagens quantitativas que os usuarios podem tentar entender ou comunicar a partir de um conjunto de dados e os graficos associados usados para ajudar a comunicar a mensagem. Os clientes que especificam os requisitos e os analistas que executam a analise de dados podem considerar essas mensagens no decorrer do processo.
- Serie temporal
: uma unica variavel e capturada ao longo de um periodo de tempo, como a taxa de desemprego em um periodo de 10 anos. Um
grafico de linha
pode ser usado para demonstrar a tendencia.
- Classificacao: subdivisoes categoricas sao classificadas em ordem crescente ou decrescente, como uma classificacao de desempenho de vendas (a
medida
) por vendedores (a
categoria
, com cada vendedor uma
subdivisao categorica
) durante um unico periodo. Um
grafico de barras
pode ser usado para mostrar a comparacao entre os vendedores.
- Parte para todo: subdivisoes categoricas sao medidas como uma proporcao do todo (ou seja, uma porcentagem de 100%). Um
grafico de pizza
ou de barras pode mostrar a comparacao de proporcoes, como a participacao de mercado representada pelos concorrentes em um mercado.
- Desvio: as subdivisoes categoricas sao comparadas com uma referencia, como uma comparacao entre despesas reais e orcadas para varios departamentos de uma empresa em um determinado periodo. Um grafico de barras pode mostrar a comparacao do valor real com o de referencia.
- Distribuicao de frequencia: mostra o numero de observacoes de uma determinada variavel para determinado intervalo, como o numero de anos em que o retorno do mercado de acoes esta entre intervalos como 0?10%, 11?20%, etc. Um
histograma
, um tipo de grafico de barras, pode ser usado para esta analise.
- Correlacao: comparacao entre observacoes representadas por duas variaveis (X, Y) para determinar se elas tendem a se mover na mesma direcao ou em direcoes opostas. Por exemplo, tracando o desemprego (X) e a inflacao (Y) para uma amostra de meses. Um
grafico de dispersao
e normalmente usado para esta mensagem.
- Comparacao nominal: comparar subdivisoes categoricas sem uma ordem especifica, como o volume de vendas por codigo de produto. Um grafico de barras pode ser usado para esta comparacao.
- Geografico ou geoespacial: comparacao de uma variavel em um mapa ou layout, como a taxa de desemprego por estado ou o numero de pessoas nos varios andares de um edificio. Um
cartograma
e um grafico tipico usado.
[
11
]
[
12
]
O autor
Jonathan Koomey
recomendou uma serie de boas praticas para a compreensao de dados quantitativos. Essas incluem:
- Verificar se ha anomalias nos dados brutos antes de realizar uma analise;
- Executar novamente calculos importantes, como verificar colunas de dados resultantes de formulas;
- Confirme se os totais principais sao a soma dos subtotais;
- Verifique as relacoes entre os numeros que devem ser relacionados de maneira previsivel, como proporcoes ao longo do tempo;
- Normalizar numeros para tornar as comparacoes mais faceis, como analisar valores por pessoa ou em relacao ao PIB ou como um valor de indice em relacao a um ano base;
- Divida os problemas em partes componentes, analisando os fatores que levaram aos resultados, como a analise DuPont do retorno sobre o patrimonio liquido.
[
8
]
Para as variaveis em exame, os analistas normalmente obtem
estatisticas descritivas
para elas, como a media,
mediana
e
desvio padrao
. Eles tambem podem analisar a
distribuicao
das variaveis-chave para ver como os valores individuais se agrupam em torno da media.
 Uma ilustracao do principio MECE usado para a analise de dados
Uma ilustracao do principio MECE usado para a analise de dados
Os consultores da
McKinsey & Company
nomearam uma tecnica para decompor um problema quantitativo em suas partes componentes, chamada de principio MECE. Cada camada pode ser dividida em suas componentes; cada uma das subcomponentes deve ser
mutuamente exclusiva
uma da outra e, coletivamente, ter como soma a camada acima deles. O relacionamento e conhecido como "Mutuamente Exclusivo e Coletivamente Exaustivo" ou MECE. Por exemplo, o
lucro
, por definicao, pode ser dividido em receita total e custo total. Por sua vez, a receita total pode ser analisada por suas componentes, como a receita das divisoes A, B e C (que sao mutuamente exclusivas entre si) e devem ter como soma a receita total (exaustivas coletivamente).
Os analistas podem usar medicoes estatisticas robustas para resolver certos problemas analiticos. O
teste de hipoteses
e usado quando uma hipotese particular sobre o verdadeiro estado de coisas e feita pelo analista e sao reunidos dados para determinar se esse estado de coisas e verdadeiro ou falso. Por exemplo, a hipotese pode ser que "O desemprego nao tem efeito sobre a inflacao", o que se relaciona a um conceito economico denominado
Curva de Phillips
. O teste de hipoteses envolve a consideracao da probabilidade de erros do tipo I e do tipo II, que se relacionam ao fato de os dados apoiarem a aceitacao ou rejeicao da hipotese.
A
analise de regressao
pode ser usada quando o analista esta tentando determinar ate que ponto a variavel independente X afeta a variavel dependente Y (por exemplo, "Ate que ponto as mudancas na taxa de desemprego (X) afetam a taxa de inflacao (Y)?" ) Esta e uma tentativa de modelar ou ajustar a equacao de uma reta ou curva aos dados, de forma que Y seja uma funcao de X.
A
analise de condicao necessaria
(NCA) pode ser usada quando o analista esta tentando determinar ate que ponto a variavel independente X permite a variavel Y (por exemplo, "Ate que ponto uma determinada taxa de desemprego (X) e necessaria para uma determinada taxa de inflacao (Y)?"). Considerando que a analise de regressao (multipla) usa logica aditiva onde cada variavel X pode produzir o resultado e os Xs podem compensar uns aos outros (eles sao suficientes, mas nao necessarios), a analise de condicao necessaria (NCA) usa logica de necessidade, em que uma ou mais das variaveis X permitem que o resultado exista, mas podem nao produzi-lo (elas sao necessarias, mas nao suficientes). Cada condicao necessaria deve estar presente e a compensacao nao e possivel.
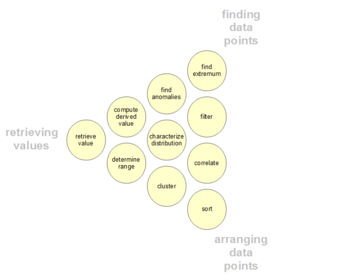
Os usuarios podem ter pontos de dados especificos de interesse em um conjunto de dados, ao contrario das mensagens gerais descritas anteriormente. Essas atividades analiticas do usuario de baixo nivel sao apresentadas na tabela a seguir. A taxonomia tambem pode ser organizada por tres polos de atividades: recuperacao de valores, localizacao de pontos de dados e organizacao de pontos de dados.
[
13
]
[
14
]
[
15
]
[
16
]
| #
|
Tarefa
|
Descricao Geral
|
Resumo padrao
|
Exemplos
|
| 1
|
Recuperar valor
|
Dado um conjunto de casos especificos, encontrar atributos desses casos.
|
Quais sao os valores dos atributos {X, Y, Z, ...} nos casos de dados {A, B, C, ...}?
|
- Qual e a quilometragem por galao do Ford Mondeo?
- Quanto tempo dura o filme E o Vento Levou?
|
| 2
|
Filtrar
|
Dadas algumas condicoes concretas sobre os valores dos atributos, encontrar casos de dados que satisfacam essas condicoes.
|
Quais casos de dados satisfazem as condicoes {A, B, C, ...}?
|
- Quais cereais Kellogg's tem alto teor de fibras?
- Quais comedias ganharam premios?
- Quais fundos tiveram desempenho inferior ao SP-500?
|
| 3
|
Calcular Valor Derivado
|
Dado um conjunto de casos de dados, calcular uma representacao numerica agregada desses casos de dados.
|
Qual e o valor da funcao de agregacao F sobre um determinado conjunto S de casos de dados?
|
- Qual e o conteudo calorico medio dos cereais Post?
- Qual e a receita bruta de todas as lojas combinadas?
- Quantos fabricantes de automoveis existem?
|
| 4
|
Encontrar Extremo
|
Encontrar casos de dados que possuem um valor extremo de um atributo em seu intervalo no conjunto de dados.
|
Quais sao os N casos de dados com os maiores/menores valores do atributo A?
|
- Qual e o carro com maior MPG?
- Qual diretor/filme ganhou mais premios?
- Qual filme da Marvel Studios tem a data de lancamento mais recente?
|
| 5
|
Ordenar
|
Dado um conjunto de casos de dados, ordena-los de acordo com alguma metrica ordinal.
|
Qual e a ordem de classificacao de um conjunto S de casos de dados de acordo com seus valores para o atributo A?
|
- Ordenar os carros por peso.
- Classificar os cereais por calorias.
|
| 6
|
Determinar Intervalo
|
Dado um conjunto de casos de dados e um atributo de interesse, encontrar o intervalo de valores dentro do conjunto.
|
Qual e a faixa de valores do atributo A em um conjunto S de casos de dados?
|
- Qual e a gama de comprimentos de filme?
- Qual e a faixa de potencia do carro?
- Quais atrizes estao no conjunto de dados?
|
| 7
|
Caracterizar distribuicao
|
Dado um conjunto de casos de dados e um atributo quantitativo de interesse, caracterizar a distribuicao dos valores desse atributo ao longo do conjunto.
|
Qual e a distribuicao dos valores do atributo A em um conjunto S de casos de dados?
|
- Qual e a distribuicao dos carboidratos nos cereais?
- Qual e a distribuicao da idade dos compradores?
|
| 8
|
Encontrar Anomalias
|
Identificar quaisquer anomalias dentro de um determinado conjunto de casos de dados com respeito a um determinado relacionamento ou expectativa, por exemplo,
outliers
estatisticos.
|
Quais casos de dados em um conjunto S de casos de dados tem valores inesperados/excepcionais?
|
- Existem excecoes para a relacao entre potencia e aceleracao?
- Existem outliers na proteina?
|
| 9
|
Agrupar
|
Dado um conjunto de casos de dados, encontrar grupos de valores de atributos semelhantes.
|
Quais casos de dados em um conjunto S de casos de dados sao semelhantes em valor para os atributos {X, Y, Z,. . . }?
|
- Existem grupos de cereais com gordura/calorias/acucar semelhantes?
- Existe um grupo de duracoes de filme tipicas?
|
| 10
|
Correlacionar
|
Dado um conjunto de casos de dados e dois atributos, determinar relacoes uteis entre os valores desses atributos.
|
Qual e a correlacao entre os atributos X e Y em um determinado conjunto S de casos de dados?
|
- Existe correlacao entre carboidratos e gordura?
- Existe correlacao entre pais de origem e MPG?
- Os diferentes generos tem um metodo de pagamento preferido?
- Existe uma tendencia de aumento da duracao dos filmes ao longo dos anos?
|
| 11
|
Contextualizar
[
16
]
|
Dado um conjunto de casos de dados, encontrar a relevancia contextual dos dados para os usuarios.
|
Quais casos de dados em um conjunto S de casos de dados sao relevantes para o contexto dos usuarios atuais?
|
- Existem grupos de restaurantes que oferecem alimentos com base na minha ingestao calorica atual?
|
Podem existir barreiras para uma analise eficaz entre os analistas que realizam a analise de dados ou entre o publico. Distinguir fato de opiniao, vieses cognitivos e inumeracia sao alguns dos desafios para uma analise de dados solida.
Uma analise eficaz requer a obtencao de fatos relevantes para responder a perguntas, apoiar uma conclusao ou
opiniao
formal ou testar
hipoteses
. Os fatos, por definicao, sao irrefutaveis, o que significa que qualquer pessoa envolvida na analise deve ser capaz de concordar com eles. Por exemplo, em agosto de 2010, o Congressional Budget Office (CBO) dos Estados Unidos estimou que estender os cortes de impostos de Bush de 2001 e 2003 para o periodo de 2011-2020 adicionaria aproximadamente US $ 3,3 trilhoes a divida nacional.
[
17
]
Todos devem ser capazes de concordar que realmente foi isso o que o CBO relatou; todos podem examinar o relatorio. Assim, isso e um fato. Se as pessoas concordam ou discordam do CBO e sua opiniao.
Como outro exemplo, o auditor de uma
empresa de capital aberto
deve chegar a uma opiniao formal sobre se as demonstracoes financeiras das empresas de capital aberto sao "apresentadas de forma justa, em todos os aspectos relevantes". Isso requer uma analise extensiva de dados factuais e evidencias para apoiar sua opiniao. Ao passar dos fatos as opinioes, sempre existe a possibilidade de que a opiniao esteja errada.
Existem varios
vieses cognitivos
que podem afetar negativamente a analise. Por exemplo, o
vies de confirmacao
e a tendencia de alguem buscar ou interpretar informacoes de uma forma que confirme os seus preconceitos. Alem disso, os individuos podem desacreditar informacoes que nao apoiem seus pontos de vista.
Os analistas podem ser treinados especificamente para estar cientes desses vieses e como supera-los. Em seu livro
Psychology of Intelligence Analysis
, o analista aposentado da CIA Richards Heuer escreveu que os analistas devem delinear claramente suas suposicoes e cadeias de inferencia e especificar o grau e a fonte da incerteza envolvida nas conclusoes. Ele enfatizou procedimentos para ajudar a expor e debater pontos de vista alternativos.
[
18
]
Os analistas eficazes geralmente sao adeptos de uma variedade de tecnicas numericas. No entanto, o publico pode nao ter tal proficiencia com numeros ou
numeracia
; eles sao considerados inumerados. As pessoas que comunicam os dados tambem podem tentar enganar ou desinformar, usando deliberadamente tecnicas numericas inadequadas.
[
19
]
Por exemplo, o aumento ou diminuicao de um numero pode nao ser o fator principal. Pode ser mais importante o numero relativo a outro numero, como o tamanho da receita ou gasto do governo em relacao ao tamanho da economia (PIB) ou o valor do custo em relacao a receita nas demonstracoes financeiras corporativas. Essa tecnica numerica e conhecida como normalizacao
[
8
]
ou dimensionamento comum. Existem muitas dessas tecnicas empregadas por analistas, seja ajustando pela inflacao (ou seja, comparando dados reais com nominais) ou considerando aumentos populacionais, demografia, etc. Os analistas aplicam uma variedade de tecnicas para lidar com as varias mensagens quantitativas descritas na secao anterior.
Os analistas tambem podem analisar dados sob diferentes hipoteses ou cenarios. Por exemplo, quando os analistas realizam analises de demonstracoes financeiras, eles frequentemente reformulam as demonstracoes financeiras sob diferentes suposicoes para ajudar a chegar a uma estimativa do fluxo de caixa futuro, que eles entao descontam ao valor presente com base em alguma taxa de juros, para determinar a avaliacao da empresa ou de suas acoes. Da mesma forma, o CBO analisa os efeitos de varias opcoes de politica sobre as receitas, despesas e deficits do governo dos EUA, criando cenarios futuros alternativos para medidas-chave.
Uma abordagem de analise de dados pode ser usada para prever o consumo de energia em edificios.
[
20
]
As diferentes etapas do processo de analise de dados sao realizadas a fim de obter edificios inteligentes, nos quais as operacoes de gerenciamento e controle do edificio, incluindo aquecimento, ventilacao, ar condicionado, iluminacao e seguranca, sao realizadas automaticamente, imitando as necessidades dos usuarios do edificio e otimizando recursos como energia e tempo.
Analytics
e o "uso extensivo de dados, analises estatisticas e quantitativas, modelos explicativos e preditivos e gerenciamento baseado em fatos para conduzir decisoes e acoes". E um subconjunto de
inteligencia de negocios
, que e um conjunto de tecnologias e processos que usam dados para entender e analisar o desempenho dos negocios.
[
21
]
 Atividades analiticas de usuarios de visualizacao de dados
Atividades analiticas de usuarios de visualizacao de dados
Na
educacao
, a maioria dos educadores tem acesso a um sistema de dados com o objetivo de analisar os dados de alunos.
[
22
]
Esses sistemas de dados apresentam dados aos educadores em um formato de dados
over-the-counter
(incorporando rotulos, documentacao suplementar e um sistema de ajuda e tomando decisoes chave de pacote/exibicao e conteudo) para melhorar a precisao das analises de dados dos educadores.
[
23
]
Esta secao contem explicacoes bastante tecnicas que podem ajudar os profissionais, mas estao alem do escopo tipico de um artigo da Wikipedia.
A distincao mais importante entre a fase inicial da analise de dados e a fase principal da analise e que, durante a analise inicial dos dados, a pessoa se abstem de qualquer analise que tenha como objetivo responder a questao original da pesquisa. A fase inicial de analise de dados e guiada pelas seguintes quatro questoes:
A qualidade dos dados deve ser verificada o mais cedo possivel. A qualidade dos dados pode ser avaliada de varias maneiras, usando diferentes tipos de analise: contagens de frequencia, estatisticas descritivas (media, desvio padrao, mediana), normalidade (assimetria, curtose, histogramas de frequencia), imputacao normal e necessaria:
- Analise de
observacoes extremas
: observacoes discrepantes nos dados sao analisadas para ver se parecem perturbar a distribuicao.
- Comparacao e correcao de diferencas em esquemas de codificacao: as variaveis sao comparadas com esquemas de codificacao de variaveis externos ao conjunto de dados e possivelmente corrigidas se os esquemas de codificacao nao forem comparaveis.
- Teste a variancia do metodo comum.
A escolha das analises para avaliar a qualidade dos dados durante a fase inicial de analise de dados depende das analises que serao conduzidas na fase de analise principal.
A qualidade dos
instrumentos de medicao
so deve ser verificada durante a fase inicial de analise dos dados, quando este nao for o foco ou questao de pesquisa do estudo. Deve-se verificar se a estrutura dos instrumentos de medicao corresponde a estrutura relatada na literatura.
Existem duas maneiras de avaliar a medicao:
- Analise de fatores confirmatorios
- Analise de homogeneidade (
consistencia interna
), que da uma indicacao da
confiabilidade
de um instrumento de medicao. Durante esta analise, sao inspecionadas as variancias dos itens e das escalas, o
α de Cronbach
das escalas e a mudanca no alfa de Cronbach caso um item fosse excluido de uma escala
Depois de avaliar a qualidade dos dados e das medicoes, pode-se decidir imputar dados faltantes ou realizar transformacoes iniciais de uma ou mais variaveis, embora isso tambem possa ser feito durante a fase principal de analise.
As possiveis transformacoes de variaveis sao:
[
28
]
- Transformacao de raiz quadrada (se a distribuicao difere moderadamente de uma normal)
- Transformacao de log (se a distribuicao for substancialmente diferente de uma normal)
- Transformacao inversa (se a distribuicao for muito diferente de uma normal)
- Transformacao em categorica (ordinal/dicotomico) (se a distribuicao for muito diferente de uma normal e nenhuma transformacao ajudar)
A implementacao do estudo atendeu as intencoes do projeto de pesquisa?
[
editar
|
editar codigo-fonte
]
Deve-se verificar o sucesso do procedimento de aleatorizacao, por exemplo, verificando se as variaveis de fundo e substantivas estao igualmente distribuidas dentro e entre os grupos.Caso o estudo nao necessite ou utilize procedimento de aleatorizacao, deve-se verificar o sucesso da amostragem nao aleatoria, por exemplo, verificando se todos os subgrupos da populacao de interesse estao representados na amostra.Outras possiveis distorcoes de dados que devem ser verificadas sao:
- Abandono (isso deve ser identificado durante a fase inicial de analise de dados)
- A nao resposta ao item (seja aleatorio ou nao, deve ser avaliada durante a fase inicial de analise de dados)
- Qualidade do tratamento (usando verificacoes de manipulacao).
Em qualquer relatorio ou artigo, a estrutura da amostra deve ser descrita de maneira precisa. E especialmente importante determinar exatamente a estrutura da amostra (e especificamente o tamanho dos subgrupos) quando se pretende fazer analises de subgrupo durante a fase de analise principal.As caracteristicas da amostra de dados podem ser avaliadas observando:
- Estatisticas basicas de variaveis importantes
- Graficos de dispersao
- Correlacoes e associacoes
- Tabulacoes cruzadas
Durante o estagio final, os resultados da analise de dados inicial sao documentados e sao tomadas as acoes corretivas necessarias, preferiveis e possiveis sao tomadas.
Alem disso, o plano original para as analises de dados principais pode e deve ser especificado com mais detalhes ou reescrito.
Para fazer isso, varias decisoes sobre as analises de dados principais podem e devem ser feitas:
- No caso de nao
normais
: deve-se transformar as variaveis; tornar as variaveis categoricas (ordinais/dicotomicas); adaptar o metodo de analise?
- No caso de
dados faltantes
: deve-se negligenciar ou imputar os dados faltantes; qual tecnica de imputacao deve ser usada?
- No caso de
outliers
: deve-se usar tecnicas de analise robustas?
- Caso os itens nao se enquadrem na escala: deve-se adaptar o instrumento de medicao omitindo itens, ou antes garantir a comparabilidade com outros (usos do(s)) instrumento(s) de medicao?
- No caso de subgrupos (muito) pequenos: deve-se abandonar a hipotese sobre diferencas entre os grupos ou usar tecnicas de pequenas amostras, como testes exatos ou
bootstrapping
?
- Caso o procedimento de randomizacao pareca defeituoso: pode-se e deve-se calcular os escores de propensao e inclui-los como covariaveis nas analises principais?
Varias analises podem ser usadas durante a fase inicial de analise de dados:
- Estatisticas univariadas (variavel unica)
- Associacoes bivariadas (correlacoes)
- Tecnicas graficas (graficos de dispersao)
E importante levar em consideracao os niveis de medicao das variaveis para as analises, pois tecnicas estatisticas especiais estao disponiveis para cada nivel:
- Variaveis nominais e ordinais
- Contagens de frequencia (numeros e porcentagens)
- Associacoes
- circumambulacoes (tabulacoes cruzadas)
- analise loglinear hierarquica (restrita a um maximo de 8 variaveis)
- analise loglinear (para identificar variaveis relevantes/importantes e possiveis fatores de confusao)
- Testes exatos ou reamostragem (no caso de os subgrupos serem pequenos)
- Calculo de novas variaveis
- Variaveis continuas
- Distribuicao
- Estatisticas (M, SD, variancia, assimetria, curtose)
- Expositores de caule e folha
- Boxplots
A analise nao linear e frequentemente necessaria quando os dados sao registrados a partir de um
sistema nao linear
. Os sistemas nao lineares podem exibir efeitos dinamicos complexos, incluindo
bifurcacoes
,
caos
,
harmonicos
e subarmonicos que nao podem ser analisados usando metodos lineares simples. A analise de dados nao lineares esta intimamente relacionada a identificacao do sistema nao linear.
[
34
]
Na fase principal de analise, sao realizadas analises destinadas a responder a questao de pesquisa, bem como qualquer outra analise relevante que seja necessaria para escrever o primeiro rascunho do relatorio de pesquisa.
Na fase de analise principal, pode ser adotada uma abordagem exploratoria ou confirmatoria. Normalmente, a abordagem e decidida antes de os dados serem coletados. Em uma analise exploratoria, nenhuma hipotese clara e declarada antes de analisar os dados, e os dados sao pesquisados em busca de modelos que os descrevam bem. Em uma analise confirmatoria, sao testadas hipoteses claras sobre os dados.
A
analise exploratoria de dados
deve ser interpretada com cuidado. Ao testar varios modelos ao mesmo tempo, ha uma grande chance de descobrir que pelo menos um deles e significativo, mas isso pode ser devido a um erro do tipo 1. E importante sempre ajustar o nivel de significancia ao testar varios modelos com, por exemplo, uma
correcao de Bonferroni
. Alem disso, nao se deve seguir uma analise exploratoria com uma analise confirmatoria no mesmo conjunto de dados. Uma analise exploratoria e usada para encontrar ideias para uma teoria, mas nao para testar essa teoria tambem. Quando um modelo e encontrado durante a analise exploratoria em um conjunto de dados, a continuacao dessa analise com uma analise confirmatoria no mesmo conjunto de dados pode simplesmente significar que os resultados da analise confirmatoria se devem ao mesmo erro do tipo 1 que inicialmente resultou no modelo exploratorio. A analise confirmatoria, portanto, nao sera mais informativa do que a analise exploratoria original.
E importante obter alguma indicacao sobre o quao generalizaveis sao os resultados.
Embora muitas vezes seja dificil de verificar, pode-se olhar para a estabilidade dos resultados. Os resultados sao confiaveis e reproduziveis? Existem duas maneiras principais de fazer isso.
- Validacao cruzada
. Ao dividir os dados em varias partes, podemos verificar se uma analise (como um modelo ajustado) com base em uma parte dos dados tambem se generaliza para outra parte dos dados. A validacao cruzada e geralmente inadequada, no entanto, se houver correlacoes nos dados, por exemplo, com
dados em painel
. Portanto, as vezes e necessario usar outros metodos de validacao. Para mais informacoes sobre este topico, consulte sobre validacao de
modelo estatistico
.
- Analise de sensibilidade
. Um procedimento para estudar o comportamento de um sistema ou modelo quando os parametros globais sao variados (sistematicamente). Uma maneira de fazer isso e por meio de
bootstrap
.
Entre os
softwares livres
notaveis para analise de dados estao:
- DevInfo ? Um sistema de banco de dados endossado pelo
Grupo das Nacoes Unidas para o Desenvolvimento
para monitorar e analisar o desenvolvimento humano.
- ELKI ? Um
framework
de mineracao de dados em
Java
com funcoes de visualizacao orientadas para a mineracao de dados.
- KNIME
? The Konstanz Information Miner, uma estrutura de analise de dados abrangente e amigavel.
- Orange ? Uma ferramenta de programacao visual com visualizacao de dados interativa e metodos para analise estatistica de dados,
mineracao de dados
e
aprendizado de maquina
.
- Pandas
? biblioteca para a analise de dados em
Python
.
- PAW ? Estrutura de analise de dados em FORTRAN/C desenvolvida no
CERN
.
- R
? Uma
linguagem de programacao
e ambiente de software para computacao estatistica e graficos.
- ROOT ? framework de analise de dados em
C++
desenvolvido no
CERN
.
- SciPy
? biblioteca para a analise de dados em Python.
- Dados.
Analise
? uma biblioteca
.NET
para analise e transformacao de dados.
- Julia
? uma linguagem de programacao adequada para
analise numerica
e ciencia computacional.
- Taguette - analise de dados qualitativos.
Concursos internacionais de analise de dados
[
editar
|
editar codigo-fonte
]
Diferentes empresas ou organizacoes realizam concursos de analise de dados para incentivar os pesquisadores a utilizar seus dados ou para resolver uma questao especifica usando a analise de dados. Alguns exemplos de concursos internacionais de analise de dados conhecidos sao os seguintes:
- Competicao Kaggle realizada por Kaggle
[
38
]
- Concurso de analise de dados LTPP realizado pela FHWA e
ASCE
.
[
39
]
[
40
]
- ↑
Xia, B. S., & Gong, P. (2015). Review of business intelligence through data analysis.
Benchmarking
,
21
(2), 300-311. doi:10.1108/BIJ-08-2012-0050
- ↑
Exploring Data Analysis
- ↑
Sherman, Rick (4 de novembro de 2014).
Business intelligence guidebook : from data integration to analytics
. Amsterdam: [s.n.]
ISBN
978-0-12-411528-6
.
OCLC
894555128
- ↑
a
b
c
Judd, Charles and, McCleland, Gary (1989).
Data Analysis
. [S.l.]: Harcourt Brace Jovanovich.
ISBN
0-15-516765-0
- ↑
John Tukey-The Future of Data Analysis-July 1961
- ↑
a
b
c
d
e
f
g
Schutt, Rachel;
O'Neil, Cathy
(2013).
Doing Data Science
. [S.l.]:
O'Reilly Media
.
ISBN
978-1-449-35865-5
- ↑
≪Data Cleaning≫
. Microsoft Research
. Consultado em 26 de outubro de 2013
- ↑
a
b
c
Perceptual Edge-Jonathan Koomey-Best practices for understanding quantitative data-February 14, 2006
- ↑
Hellerstein, Joseph (27 de fevereiro de 2008).
≪Quantitative Data Cleaning for Large Databases≫
(PDF)
.
EECS Computer Science Division
: 3
. Consultado em 26 de outubro de 2013
- ↑
Grandjean, Martin (2014).
≪La connaissance est un reseau≫
(PDF)
.
Les Cahiers du Numerique
.
10
: 37?54.
doi
:
10.3166/lcn.10.3.37-54
- ↑
Stephen Few-Perceptual Edge-Selecting the Right Graph for Your Message-2004
- ↑
Stephen Few-Perceptual Edge-Graph Selection Matrix
- ↑
Robert Amar, James Eagan, and John Stasko (2005)
"Low-Level Components of Analytic Activity in Information Visualization"
- ↑
William Newman (1994)
"A Preliminary Analysis of the Products of HCI Research, Using Pro Forma Abstracts"
- ↑
Mary Shaw (2002)
"What Makes Good Research in Software Engineering?"
- ↑
a
b
≪ConTaaS: An Approach to Internet-Scale Contextualisation for Developing Efficient Internet of Things Applications≫
.
ScholarSpace
. HICSS50
. Consultado em 24 de maio de 2017
- ↑
≪Congressional Budget Office-The Budget and Economic Outlook-August 2010-Table 1.7 on Page 24≫
. Consultado em 31 de marco de 2011
- ↑
≪Introduction≫
.
cia.gov
- ↑
Bloomberg-Barry Ritholz-Bad Math that Passes for Insight-October 28, 2014
- ↑
Gonzalez-Vidal, Aurora; Moreno-Cano, Victoria (2016). ≪Towards energy efficiency smart buildings models based on intelligent data analytics≫.
Procedia Computer Science
.
83
: 994?999.
doi
:
10.1016/j.procs.2016.04.213
- ↑
Davenport, Thomas and, Harris, Jeanne (2007).
Competing on Analytics
. [S.l.]: O'Reilly.
ISBN
978-1-4221-0332-6
- ↑
Aarons, D. (2009).
Report finds states on course to build pupil-data systems.
Education Week, 29
(13), 6.
- ↑
Rankin, J. (2013, March 28).
How data Systems & reports can either fight or propagate the data analysis error epidemic, and how educator leaders can help.
Presentation conducted from Technology Information Center for Administrative Leadership (TICAL) School Leadership Summit.
- ↑
Tabachnick & Fidell, 2007, p. 87-88.
- ↑
Billings S.A. "Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains". Wiley, 2013
- ↑
≪The machine learning community takes on the Higgs≫
.
Symmetry Magazine
. 15 de julho de 2014
. Consultado em 14 de janeiro de 2015
- ↑
Nehme, Jean (29 de setembro de 2016).
≪LTPP International Data Analysis Contest≫
. Federal Highway Administration
. Consultado em 22 de outubro de 2017
- ↑
≪Data.Gov:Long-Term Pavement Performance (LTPP)≫
. 26 de maio de 2016
. Consultado em 10 de novembro de 2017
- Ader, Herman J.
(2008a). ≪Chapter 14: Phases and initial steps in data analysis≫. In: Ader;
Mellenbergh
;
Hand
.
Advising on research methods : a consultant's companion
. Huizen, Netherlands: Johannes van Kessel Pub. pp. 333?356.
ISBN
9789079418015
.
OCLC
905799857
- Ader, Herman J.
(2008b). ≪Chapter 15: The main analysis phase≫. In: Ader;
Mellenbergh
;
Hand
.
Advising on research methods : a consultant's companion
. Huizen, Netherlands: Johannes van Kessel Pub. pp. 357?386.
ISBN
9789079418015
.
OCLC
905799857
- Tabachnick, BG & Fidell, LS (2007). Capitulo 4: Limpando seu ato. Dados de triagem antes da analise. Em BG Tabachnick & LS Fidell (Eds. ), Usando Estatisticas Multivariadas, Quinta Edicao (pp. 60?116). Boston: Pearson Education, Inc. / Allyn e Bacon.
- Ader, HJ & Mellenbergh, GJ (com contribuicoes de DJ Hand) (2008).
Aconselhamento sobre metodos de pesquisa: um companheiro do consultor
. Huizen, Holanda: Johannes van Kessel Publishing.
- Chambers, John M .; Cleveland, William S .; Kleiner, Beat; Tukey, Paul A. (1983).
Graphical Methods for Data Analysis
, Wadsworth / Duxbury Press.
ISBN
0-534-98052-X
- Fandango, Armando (2008).
Analise de dados Python, 2ª edicao
. Packt Publishers.
- Juran, Joseph M .; Godfrey, A. Blanton (1999).
Manual de qualidade de Juran, 5ª edicao.
Nova York: McGraw Hill.
ISBN
0-07-034003-X
- Lewis-Beck, Michael S. (1995).
Analise de dados: uma introducao
, Sage Publications Inc,
ISBN
0-8039-5772-6
- NIST / SEMATECH (2008)
Manual de Metodos Estatisticos
,
- Pyzdek, T, (2003).
Manual de Engenharia de Qualidade
,
ISBN
0-8247-4614-7
- Richard Veryard (1984).
Analise de dados pragmatica
. Oxford : Publicacoes cientificas da Blackwell.
ISBN
0-632-01311-7
- Tabachnick, BG; Fidell, LS (2007).
Usando Estatisticas Multivariadas, 5ª Edicao
. Boston: Pearson Education, Inc. / Allyn e Bacon,
ISBN
978-0-205-45938-4