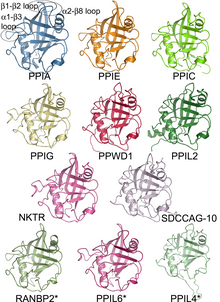
 A familia da
ciclofilina
humana representada polas estruturas dos
dominios
de
isomerase
dalguns dos seus membros.
A familia da
ciclofilina
humana representada polas estruturas dos
dominios
de
isomerase
dalguns dos seus membros.
Unha
familia de proteinas
e un grupo de
proteinas
relacionadas
evolutivamente
con estruturas, funcions e secuencias parecidas. En moitos casos unha familia de proteinas ten unha
familia de xenes
correspondente, na cal cada xene codifica a sua proteina cunha relacion de 1:1.
As proteinas dunha mesma familia descenden dun
antepasado comun
(ver
homoloxia
) e tipicamente tenen unhas
estruturas tridimensionais
e funcions similares, e unha semellanza de secuencia significativa. A mais importante destas semellanzas e a semellanza de secuencia (xeralmente na secuencia de
aminoacidos
), xa que e o indicador mais estrito de homoloxia e, por tanto, o indicador mais claro de que hai un antepasado comun. Existe un conxunto de ferramentas bastante desenvolvido para avaliar a importancia da semellanza entre un grupo de secuencias usando os metodos de
alinamento de secuencias
. As proteinas que non comparten un devanceiro comun e moi improbable que mostren unha semellanza de secuencia estatisticamente significativa, o que fai que o alinamento de secuencias sexa unha ferramenta poderosa para identificar os membros das familias proteicas.
As familias son as veces agrupadas en
clados
mais grandes chamados
superfamilias
baseandose en semellanzas estruturais ou de mecanismo de accion, mesmo cando non hai unha homoloxia de secuencia identificable.
Actualmente, definironse unhas 60.000 familias proteicas,
[
1
]
ainda que a ambiguidade na definicion de
familia proteica
(ata onde debe chegar a "semellanza"?) leva a que diferentes investigadores ofrezan cifras moi distintas.
Como ocorre con moitos termos bioloxicos, o significado de
familia de proteinas
depende do contexto no que se use; pode indicar grandes grupos de proteinas co nivel mais baixo posible de semellanza de secuencia detectable, ou grupos moi restrinxidos de proteinas con secuencias case identicas, e funcions e estruturas tridimensionais moi similares, ou un grupo de proteinas intermedio entre estes extremos. Para distinguir entre estas situacions, utilizase con frecuencia o termo
superfamilia proteica
para aquelas proteinas que so estan relacionadas distantemente cuxo parentesco non e detectable pola semellanza de secuencias, senon so por caracteristicas estruturais compartidas.
[
2
]
[
3
]
[
4
]
Acunaronse tamen outros termos como
clase
,
grupo
,
clan
e
sub-familia
de proteinas ao longo dos anos, pero todos sofren unha ambiguidade similar no seu uso. Un uso comun e que as superfamilias (homoloxia
estrutural
) contenen familias (homoloxia de secuencia) que a sua vez contenen sub-familias. Xa que logo, unha superfamilia, como a do
clan PA
de
proteases
, ten unha
conservacion de secuencias
moito menor que unha das familias que conten, por exemplo a familia C04. E improbable que se chegue a acordar unha definicion exacta, polo que depende do lector discernir como se estan usando eses termos exactamente nun determinado contexto.

O concepto de
familia de proteinas
concibiuse nun momento en que se conecian poucas estruturas e secuencias de proteinas; daquela, as que se comprendian estruturalmente eran principalmente pequenas proteinas de dominio unico como a
mioglobina
,
hemoglobina
, e o
citocromo c
. Desde enton, descubriuse que moitas proteinas comprenden moitas unidades funcionais e estruturais independentes ou
dominios
. Debido a mesturanza ou reorganizacion evolutiva, diferentes dominios dunha proetina evolucionaron independentemente. Isto levou en anos recentes a centrar a atencion nos dominios e familias proteicos. Varios recursos en lina estan dedicados a identificar e catalogar eses dominios (ver lista de ligazons ao final deste artigo).
As rexions de cada proteina tenen diferentes restricions funcionais (caracteristicas esenciais para a funcion e estrutura da proteina). Por exemplo, o
sitio activo
dun
encima
require que certos residuos de aminoacidos estean orientados de modo preciso nas tres dimensions. Por outra parte, unha interface de union proteina-proteina pode consistir en grandes superficies con restricions de
hidrofobicidade
ou polaridade dos residuos de aminoacidos. As rexions funcionalmente restrinxidas das proteinas evolucionan mais lentamente que as rexions non restrinxidas como os bucles superficiais, que dan lugar a bloques discernibles de secuencias conservadas cando se comparan as secuencias dunha familia proteica (ver
alinamento multiple de secuencias
). Estes bloques denominanse xeralmente
motivos
, ainda que se tenen usado moitos outros termos (bloques, sinaturas, pegadas dactilares etc.). Tamen para isto hai un gran numero de recursos en lina que se dedican a identificar e catalogar os motivos proteicos (ver a lista do final deste artigo).
Evolucion das familias de proteinas
[
editar
|
editar a fonte
]
Segundo o consenso actual, as familias proteicas orixinanse de dous xeitos. Primeiramente, a separacion dunha especie parental en duas especies descendentes illadas xeneticamente permite que se acumulen independentemente variacions nun xene/proteina (
mutacions
) nestas duas linaxes. Isto ten como resultado a formacion dunha familia de proteinas
ortologas
, xeralmente con motivos de secuencia conservados. En segundo lugar, unha duplicacion xenica pode crear unha segunda copia dun xene (denominado
paralogo
). Como o xene orixinal ainda pode realizar a sua funcion, o xene duplicado e libre de diverxer e pode adquirir novas funcions (por mutacion aleatoria). Certas familias de xenes/proteinas, especialmente en
eucariotas
, sofren unha expansion e contraccion extremas no decurso da
evolucion
, as veces conxuntamente con
duplicacions xenomicas
completas. Esta expansion e contraccion de familias proteicas e unha das caracteristicas salientables da
evolucion xenomica
, pero a sua importancia e ramificacions ainda non estan claras.
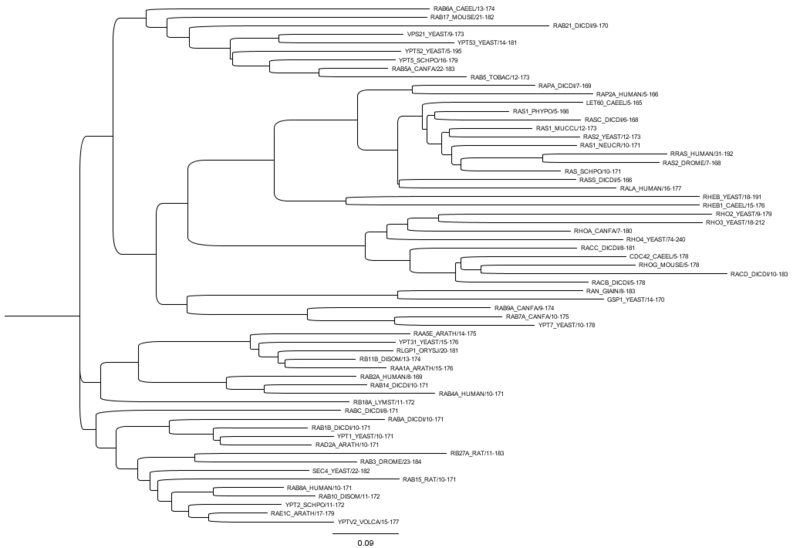 Arbore filoxenetica
a
superfamilia Ras
. A arbore xerouse utilizando FigTree (un
programa informatico
en lina).
Arbore filoxenetica
a
superfamilia Ras
. A arbore xerouse utilizando FigTree (un
programa informatico
en lina).
Uso e importancia das familias de proteinas
[
editar
|
editar a fonte
]
A medida que se incrementa o numero de proteinas
secuenciadas
e aumenta o interese na analise do
proteoma
, estanse a facer esforzos por organizar as proteinas en familias e por describir os dominios e motivos que os componen. Unha identificacion fiable das familias de proteinas e basica na analise
filoxenetica
, na anotacion funcional, e na exploracion da diversidade de funcions das proteinas nunha rama filoxenetica dada. A
Enzyme Function Initiative
(EFI) esta usando as familias e superfamilias proteicas como base para o desenvolvemento dunha estrartexia baseada en secuencia/estrutura para facer asignamentos funcionais a grande escala de encimas de funcion desconecida.
[
5
]
Os medios algoritmicos para establecer familias de proteinas a grande escala estan baseados na nocion de semellanza. A maioria das veces a unica semellanza a que se ten acceso e a semellanza de secuencia.
Recursos sobre familias de proteinas
[
editar
|
editar a fonte
]
Hai moitas
bases de datos
bioloxicas que rexistran exemplos de familias proteicas e permiten aos usuarios identificar se as novas proteinas que se identifican pertencen a unha nova familia. Velaqui alguns exemplos:
- Pfam
- Base de datos de familias de alinamentos e
HMMs
- PROSITE
- Base de datos de
dominios proteicos
, familias e sitios fncionais
- PIRSF
-
SuperFamily Classification System
(Sistema de Clasificacion de Superfamilias)
- PASS2 -
Protein Alignment as Structural Superfamilies v2
(Alinamento de Proteinas como Superfamilias Estruturais v2) - PASS2@NCBS
[
6
]
- SUPERFAMILY
- Libraria de HMMs que representan superfamilias e bases de datos de anotacions (de superfamilias e familias) para todos os organismos completamente secuenciados
- SCOP
e
CATH
- clasificacions de estruturas de proteinas en superfamilias, familias e dominios
De xeito similar existen moitos
algoritmos
de busca de bases de datos, como por exemplo:
- ↑
Kunin, V.; Cases, I.; Enright, A. J.; De Lorenzo, V.; Ouzounis, C. A. (2003).
"Myriads of protein families, and still counting"
.
Genome Biology
4
(2): 401.
PMC
151299
.
PMID
12620116
.
doi
:
10.1186/gb-2003-4-2-401
.
- ↑
Dayhoff, M. O.
(1974). "Computer analysis of protein sequences".
Federation proceedings
33
(12): 2314?2316.
PMID
4435228
.
- ↑
Dayhoff, M. O.
; McLaughlin, P. J.; Barker, W. C.; Hunt, L. T. (1975). "Evolution of sequences within protein superfamilies".
Die Naturwissenschaften
62
(4): 154.
doi
:
10.1007/BF00608697
.
- ↑
Dayhoff, M. O.
(1976). "The origin and evolution of protein superfamilies".
Federation proceedings
35
(10): 2132?2138.
PMID
181273
.
- ↑
Gerlt, J. A.; Allen, K. N.; Almo, S. C.; Armstrong, R. N.; Babbitt, P. C.; Cronan, J. E.; Dunaway-Mariano, D.; Imker, H. J.; Jacobson, M. P.; Minor, W.; Poulter, C. D.; Raushel, F. M.; Sali, A.; Shoichet, B. K.; Sweedler, J. V. (2011).
"The Enzyme Function Initiative"
.
Biochemistry
50
(46): 9950?9962.
PMC
3238057
.
PMID
21999478
.
doi
:
10.1021/bi201312u
.
- ↑
Gandhimathi, A.; Nair, A. G.; Sowdhamini, R. (2011).
"PASS2 version 4: An update to the database of structure-based sequence alignments of structural domain superfamilies"
.
Nucleic Acids Research
40
(Database issue): D531?D534.
PMC
3245109
.
PMID
22123743
.
doi
:
10.1093/nar/gkr1096
.
- ↑
Emms DM, Kelly S. (Aug 2015). "OrthoFinder: solving fundamental biases in whole genome comparisons dramatically improves orthogroup inference accuracy.".
Genome Biology.
16
(157).
PMID
26243257
.
doi
:
10.1186/s13059-015-0721-2
.